一、前言
在AI时代,大量AI大模型层出不穷,囊括了生活的方方面面。
但遗憾的是,这些大模型往往与涉密行业有着极大的冲突
【隐私泄露】
这些大模型通常由各公司所提供,要使用这些模型,需要把数据或者资料上传到这些公司。
虽然大公司们总会拍胸脯保证不会偷看资料内容。
但谁又能保证呢?
作为法律行业或其他保密岗位人员来说
泄露秘密=前途尽毁
还好我们可以本地部署大模型(甚至可离线使用),尽可能避免泄露数据的问题。
基于此,笔者基于魔搭社区(http://modelscope.cn)中,阿里巴巴通义实验室分享的语音转文本大模型,搭建了一个简易的应用。
工具完全开源,希望大家一起体验AI大模型的魅力。
(再也不用买某家好贵的语音转文本服务了)
二、仓库地址
可git clone,或直接下载仓库内全部文件
https://github.com/ByronLeeeee/SimpleSpeechTranscription三、使用说明
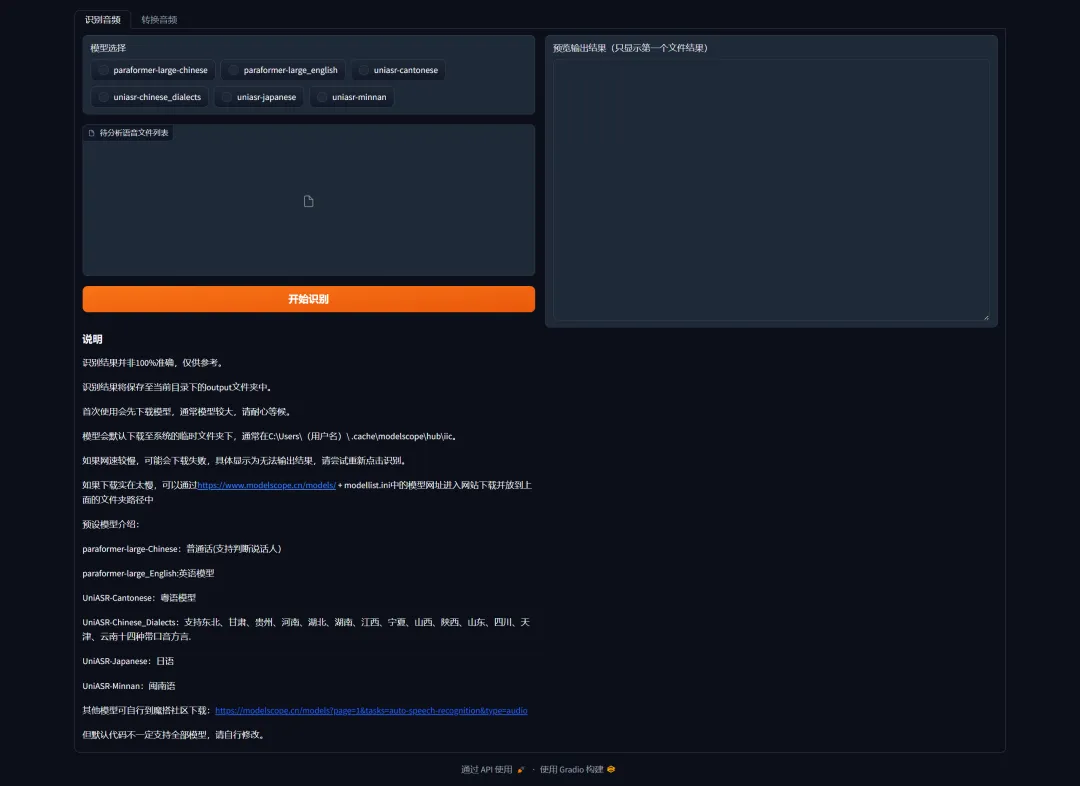
项目使用了Gradio库作为WebUI,基本用法也硬编码到界面上,基本只需要放入音频-点击按钮转换-在本地文件夹找到输出的文本文件即可。
必备环境
– Python 3.10以上
– FFMPEG(为了转音频格式,提前准备、配置也可,如程序未发现也会自己下载安装)
– 代码仅在Windows环境下进行了测试,其他系统请自行测试
– 请通过以下方式安装依赖:
pip install -r requirements.txt使用步骤

一共有4个文件夹,用途如上图。
【音频识别】
只需要把待转换的wav文件放到wav文件夹,支持同时识别多个文件。
打开程序或刷新网页即可自动读取出可识别的音频文件列表,点击【开始识别】按钮即可进行语音转换文本。
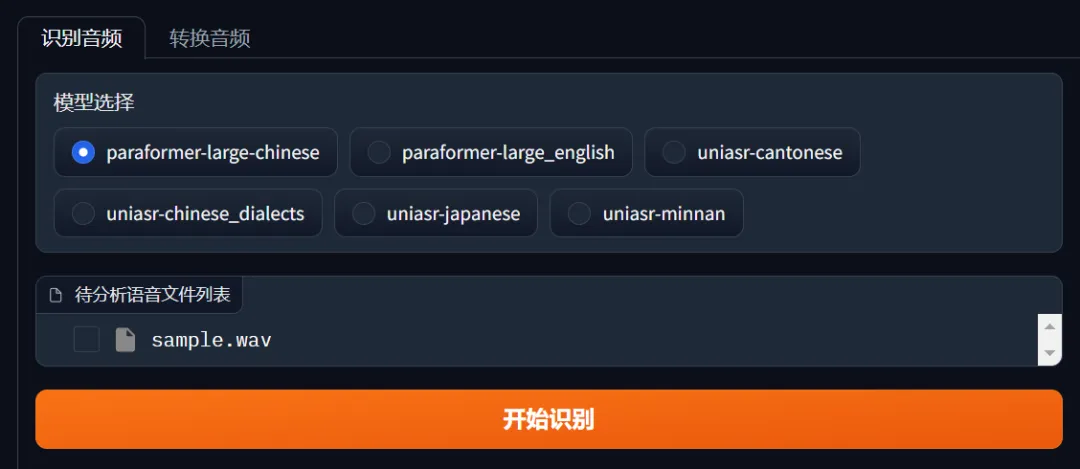
成功转换后,右侧会出现首个文件的全文结果:
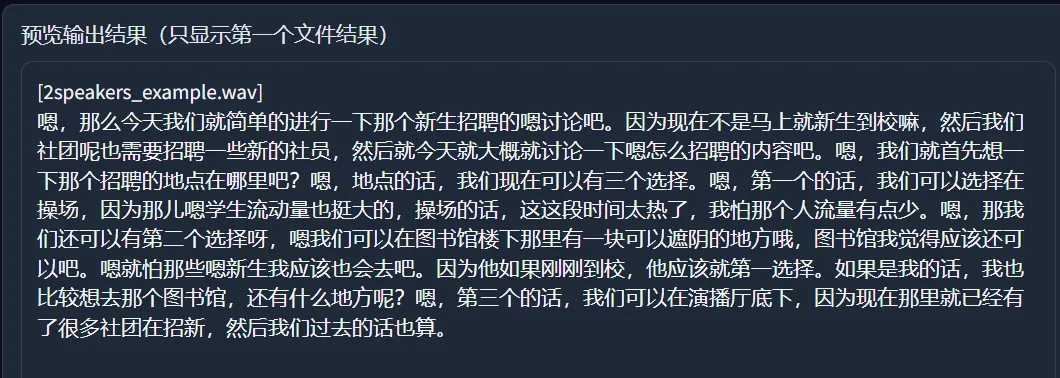
同时在output文件夹生成和音频同名称的两个txt文件


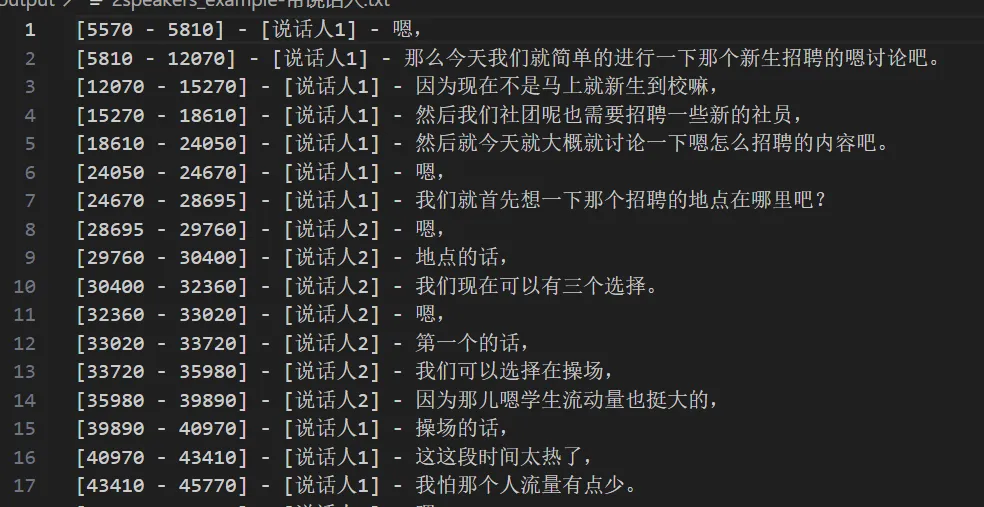
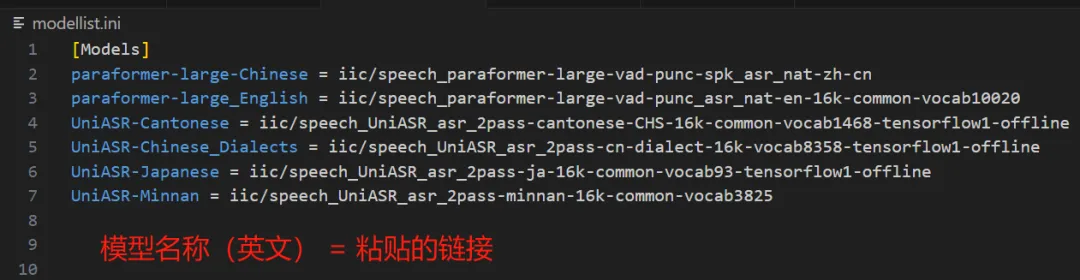
目前笔者在魔搭中预先找了一些模型:

其他模型可以在魔搭寻找,把模型链接粘贴到modellist.ini文件中,重启程序即可:

【格式转换】
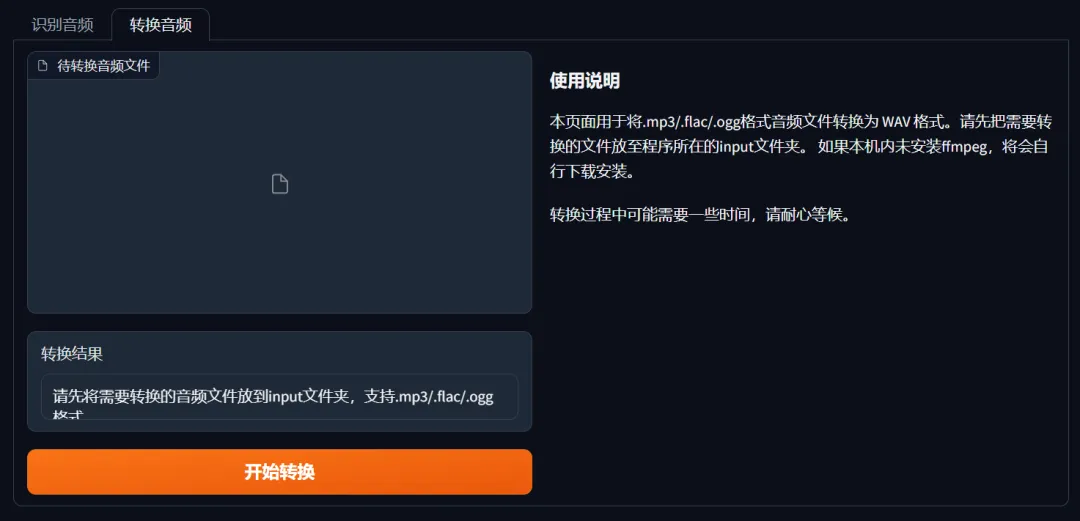
因模型通常只支持wav格式文件针对MP3/FLAC等格式的音频文件需要进行转换
只需要把音频文件放到input文件夹,然后点击转换即可
转换成功后会自动保存到wav文件夹,切换回“识别音频”标签页或者刷新网页后即可看到转换后的文件。
四、补充
【下载速度慢】
首次使用模型会先进行下载,然后魔搭目前下载速度不一定稳定,可能会耗费时间较长,请耐心等候。
也可以直接在网页中下载模型放到本地路径。
【请勿更新modelscope和funasr库】
阿里最近更新了modelscope和funasr库,但调用方式和以往完全不同。
本工具代码并不支持新库的调用方式,请保持requirements.txt中的版本号
funasr==0.8.7
modelscope==1.9.5如有其他使用问题,欢迎留言或github提issues。

北京市隆安(广州)律师事务所律师、隆安湾区人工智能法律研究中心高级顾问。具有近十年互联网法律实务经验,曾先后为创业板上市互联网企业、全国互联网综合实力 50 强企业、互联网快时尚零售独角兽等互联网企业提供法律服务,擅长办理互联网类企业诉讼与合规业务,擅于通过计算机技术手段深度挖掘证据。
您可以通过以下方式联系我: 电子邮箱:liboyang@lslby.com 微信号:legal-lby