近日,随着DeepSeek热潮,不断有各类技巧分享文章在网上流传
其中不乏大量由专业法律机构、律所、律师、法务发布的文章
这个热潮在当年GPT-3.5发布时就已出现过,这次随着DeepSeek大火,法律行业又重新开始了,甚至有更多人加入了这个热潮
但令人疑惑的是,很多一直存在的误解、误区同样再次被作为“技巧”分享
甚至还加入了大量“脑补”内容,实在令人“忍俊不禁”
接下来就让我们看看,到底哪些是误解,这些误解又有多离谱
*本文仅为笔者个人观点,不视为任何法律建议或法律意见。
**本文如有截图仅为示例,不作为对原作者的批评
一、常见基础误解
先来讲讲几个常见误解,有利于后续判断各类“误区技巧”
误解一:DeepSeek推理模型最强,不要用普通模型
实际:推理模型会因为反复“多角度思考”而导致想太多
官网V3(普通模型):
官网R1(推理模型):

R1经过长时间思考后,虽然在思考过程中曾经出现了正确答案,但因思考角度过多,导致最终污染了最终输出结果
对于不需要过多思考的问题,不分场合使用推理模型反而容易得出错误结果
误解二:DeepSeek的回答总是正确的
实际:目前大语言模型(LLM)的核心原理是“根据上下文预测最可能的下一个词”,而非真正理解内容。任何LLM对其输出的正确性和真实性都无法完全保证,这就是所谓的“幻觉”问题
仅有极少数AI模型在回答前会进行一定程度的”思考”或”判断”。绝大多数AI都会直接基于用户输入生成回答,不会主动拒绝回应(除非遇到明确限制的问题)。即使面对训练数据中从未出现过的内容,AI也会根据词语概率分布生成看似合理但可能不准确的回答
何况,AI甚至连对文本内容的归纳总结都无法保证是准确的
这一点与下一个误解结合起来看,大家将会对AI的局限性有更清晰的认识
误解三:联网搜索值得信赖
实际:联网搜索的原理是将用户的问题发送至搜索引擎API,获取网页结果后,AI根据这些内容直接进行归纳总结后,回复用户的问题;AI不会对内容的真伪进行判断。因此,回复的准确性完全取决于网页结果中他人发布的信息
甚至,AI在归纳网页内容时,也可能出现错误
以下为一个例子:
在使用DeepSeek的联网搜索功能时,询问:“请分析(2025)粤0103民初9999号案件。” DeepSeek随即启动网页搜索,检索了50个网页并返回了一份看似详尽的回答。回答内容涵盖案件背景、判决结果、法律程序及意义等等,甚至附上了信息来源,看起来颇具可信度

然而,只要查看信息来源的标题,就已经能发现明显问题:真实的案件来源于广州番禺区人民法院,且案号完全不同
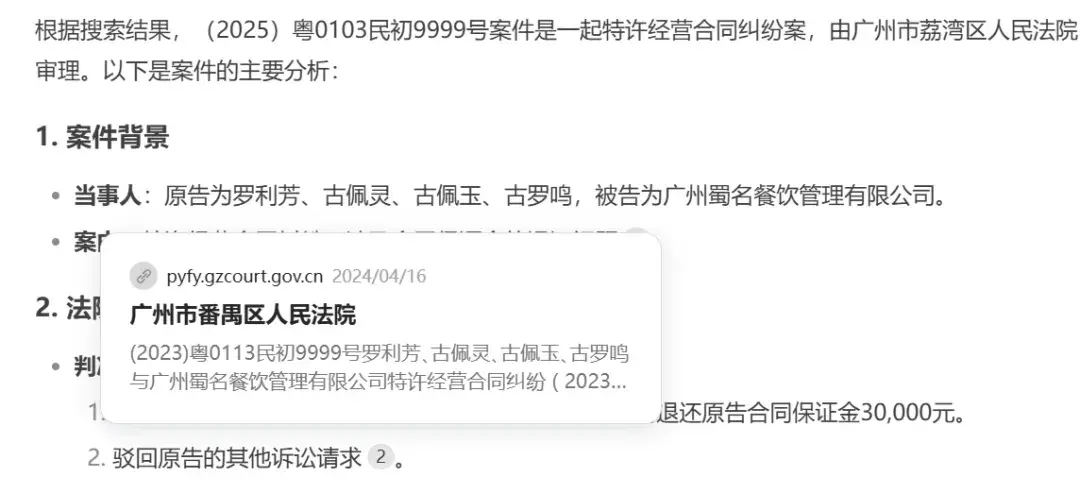
实际网页内容是这样的

DeepSeek的回答究竟有多少错误?
1. 案号错误:实际为“(2023)粤0113民初9999号”,误写为“(2025)粤0103民初9999号”。
2. 审理法院错误:实际为番禺区人民法院,误写为荔湾区人民法院。
3. 上诉法院错误:实际应上诉至广州知识产权法院,且上诉状提交至番禺区人民法院,而非误写的广州市中级人民法院。
4. 法律依据错误:公告仅涉及程序性送达问题,而非依据《中华人民共和国民事诉讼法》进行案件审理。
5. 文本类型错误:实际为送达公告,而非判决书。
上述错误还仅仅来源于DeepSeek对单一简单网页(未超出上下文限制)的归纳。如果数据来源于更多网页,且每个网页内容冗长、超出AI的上下文窗口,错误率和不可靠性可能会进一步增加
即使启用联网搜索功能,仍未能完全消除“幻觉”问题,仍需逐一核验每个信息来源的准确性
切勿直接采信AI生成的任何输出文本
误解四:在单个聊天窗口中投喂/训练自己的AI
目前市面上全部大语言模型(LLM)都有一个显著限制:上下文长度是有限的。虽然一些模型已将上下文扩展到1M甚至2M(约200万Tokens),但依然摆脱不了“有限”的本质
很多人以为,只要在聊天窗口中不断输入自己的材料,就能让AI“学习”或“记住”这些内容,实现所谓的“投喂”或“训练”
然而,这种想法其实是一种误解,根本算不上真正的训练
首先最核心的一点是,AI的“知识”主要来源于其初始训练时的参数,而不是用户临时输入的数据
在聊天窗口中,用户提供的材料仅作为当前对话的临时上下文,AI会结合这些内容和自身参数生成回答。但当对话超出上下文窗口限制时,较早的信息会被自动丢弃,AI只能参考后续内容。这就是为什么“单窗口对话会越来越笨”——最早的文本早已被忘得一干二净
AI不像人类那样能积累知识,也无法通过单一会话的反复输入提升对某领域的理解。即使你在某个窗口塞入海量信息,一旦打开新窗口,AI仍会“失忆”,因为它的“记忆”仅限于单次会话的有限的上下文
真正的AI训练需要专业的技术框架、海量标注数据和复杂的反向传播算法来调整模型权重,而非简单地在聊天框中堆砌材料
当然,用户输入的内容可能被AI公司收集,作为下一代模型训练的素材,实现另一种形式的“训练”,但那是另一个话题了
二、各类“奇妙”技巧
因最大上下文限制(笑),对AI的基础知识分享暂时到这里,下面就看看最近笔者在网上看到的各类“奇妙”的技巧
甚至连笔者这种资深AI使用者都不由自主“啧啧称奇”
注意:以下示例来源公开的各类公众号文章,仅用于节选举例(内容太多了,只举一部分笔者认为最奇妙的),如确实存在这种技巧,只是笔者无知的,笔者先行道歉
“技巧”一:DeepSeek会自动爬虫

DeepSeek在没有API配合的情况下,设置任何指令都不能自动抓取任何最新监管动态,何况爬虫也不是LLM的能力范围之内,是爬虫程序/联网搜索API的功劳
此外,DeepSeek也不能生图(当然,可以通过生成HTML的形式显示,但目前看到的各类分享文章,知道DeepSeek有HTML显示能力的寥寥)
“技巧”二:DeepSeek可以做类案搜索



实际上,DeepSeek没有接入任何案件数据库,并不具备“类案检索”的能力,从上文的误区可知,就算开启联网功能,直接把检索结果嵌入报告的可能性也不高

同样也不具备基于历史判决量化概率的能力

同样也无法筛选出关键案例
(如果是调用API一份份文书看过去,那心疼API费用)
“技巧”三:DeepSeek可通过反馈指令提升准确率

DeepSeek没有/feedback指令,且正如前述,正常的用户回复不会用于【训练自己的模型】,是否用指令对于下次使用没有任何影响
真正有助于DeepSeek训练的功能是这两个按钮,可用于给DeepSeek进行人类偏好微调

因此,如果想帮助DeepSeek训练,可多多按这两个按钮
“技巧”四:DeepSeek有“修订”模式

DeepSeek仅能通过文本格式输出内容,不具备“修订模式”的功能,也不能直接操作Word/WPS
如果真的需要此类功能,建议使用笔者的Word/WPS 插件
【WordOllama】发布 | 为Word增加AI功能 | 支持本地模型、CHatGPT和国产大模型
“技巧”五:DeepSeek可以解析哈希值
DeepSeek只是大语言模型,不具备验证哈希值的能力,同样也无法用于验证区块链的上链时间和内容完整性
“技巧”六:DeepSeek可以检查并调整格式
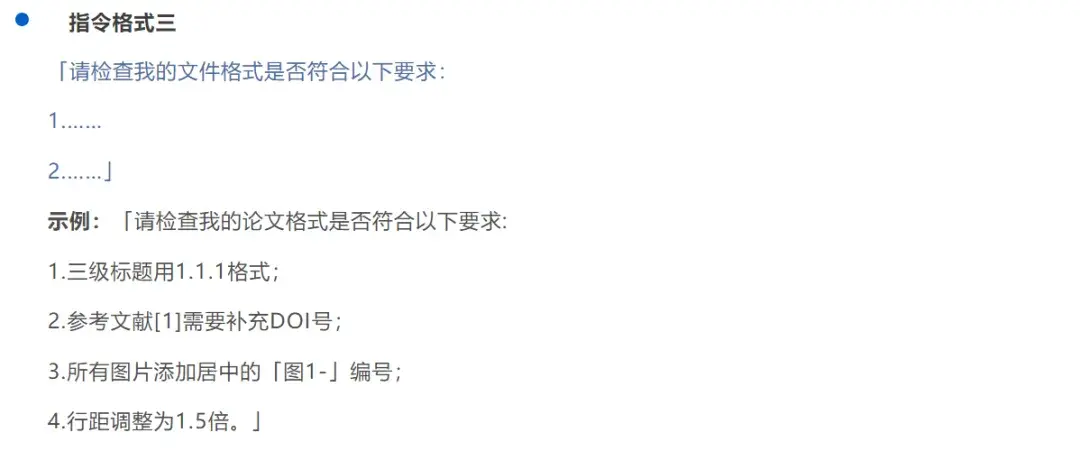
输入给DeepSeek的文本都会自动转化为【纯文本】格式,不管原文格式是什么,发给DeepSeek看的通通是纯文本
同理,DeepSeek返回的格式也不会带任何“居中”、“行距”的格式数据,标题格式也只会用纯文本方式输出,还是需要手动在Word/WPS中自行调整格式
甚至因为全文被改,要调整回来的格式更多了
“技巧”七:DeepSeek可以转录音频文件

DeepSeek是比较【纯粹】的大语言模型,不具备任何转录音频的能力,同时更不可能在音频中区分说话人、知道谁是甲方谁是乙方
甚至,DeepSeek连读图的能力都没有,仅仅能OCR图片中的文字
“技巧”八:DeepSeek可以取代“XX查”

除非接入了“XX查”的API或者自行搭建了企业信息数据库,且通过API工作流的方式调取数据,否则DeepSeek不具备单纯通过调查对象信息就能进行尽职调查的能力
此外,除非将上述数据一口气提供(且还不超过最长上下文限制),DeepSeek无法分析“重大合同履行情况以及是否存在潜在的法律纠纷”的能力,因为DeepSeek没有这些数据,强行要DeepSeek回答,只会“瞎掰”一个结论出来(“幻觉”)
“技巧”九:DeepSeek可以“忘记上传内容”

任何人在聊天窗口中都不能对DeepSeek的服务器进行任何更改
当使用DeepSeek或其他AI时,无论是用户输入的文本或者上传给AI的文件,都会【有期限】或【无期限】地保存在AI服务商的服务器中,目前,用户的任何指令都无法要求AI进行任何撤回的工作
而相关资料则会成为DeepSeek训练下一代模型的参数来源(其他模型服务同理)

(再者,如果用户真的能调动DeepSeek的服务器,那有人下指令“格式化你的服务器”又该怎么办?)
三、暂时结语
因为篇幅有限,暂时先写个(一),本文暂告一段落 —— 作为一名律师,我真心希望无需再写(二)(三)(四),毕竟写科普远比制造话题耗费精力
写这篇文章,我无意指摘任何人,只是想以律师的视角呼吁:法律行业讲究证据为王、逻辑为本,在撰写文章或追热点时,能否先回归职业本能,去核查一下材料的真伪?而不是看到几篇公众号文章就匆忙“参考”,甚至让AI自己炮制使用指南——这与我们在法庭上追求严谨的态度,实在相去甚远
尤其当我们以律所或专业身份发声时,每一篇文章都承载着公众对法律人的信任。短期的流量或许诱人,但若内容失实,损害的不仅是个人或律所的信誉,更是整个行业在公众眼中的分量
作为法律人,我们的每一篇“科普”、每一次“分享”,都应如法庭上的辩词,守护事实之基石,而非为谣言铺路,更不可为流量折腰
若连法律人都弃真逐浪,何以让世人信服法之威严?

北京市隆安(广州)律师事务所律师、隆安湾区人工智能法律研究中心高级顾问。具有近十年互联网法律实务经验,曾先后为创业板上市互联网企业、全国互联网综合实力 50 强企业、互联网快时尚零售独角兽等互联网企业提供法律服务,擅长办理互联网类企业诉讼与合规业务,擅于通过计算机技术手段深度挖掘证据。
您可以通过以下方式联系我: 电子邮箱:liboyang@lslby.com 微信号:legal-lby