这个春节期间,要说谁最红,那肯定是DeepSeek-R1
整个春节,无论是新闻网站、长短视频网站还是亲戚长辈的口中,都能听到(看到)这个名字
各类文章视频轰炸下,相信在这里也不需要过多介绍DeepSeek了
但AI红,自然是非多,伴随而来的,是各种“蹭热度”的资讯,例如:
“三分钟教你本地部署DeepSeek-R1″
“用Ollama+DeepSeek-R1打造你的AI助理”
“本站已接入DeepSeek-R1,欢迎使用”
但是,这个“DeepSeek”真的是“DeepSeek”吗?
各类混乱的文章和标题党,实在让笔者忍不住“好为人师”,想简单介绍一下目前的开源DeepSeek问题
*本文仅为笔者个人观点,不视为任何法律建议或法律意见。
一、开源的DeepSeek-R1
DeepSeek(又或者说深度求索公司)一直都是开源的先锋
在2023年末发布的DeepSeek LLM(第一代)开始,DeepSeek就是开源的,任何人都可以在自己的设备上自行部署各类DeepSeek模型
从23年至今,深度求索已经发布了包括大语言和图像在内的68款模型,堪称真 · Open的AI公司
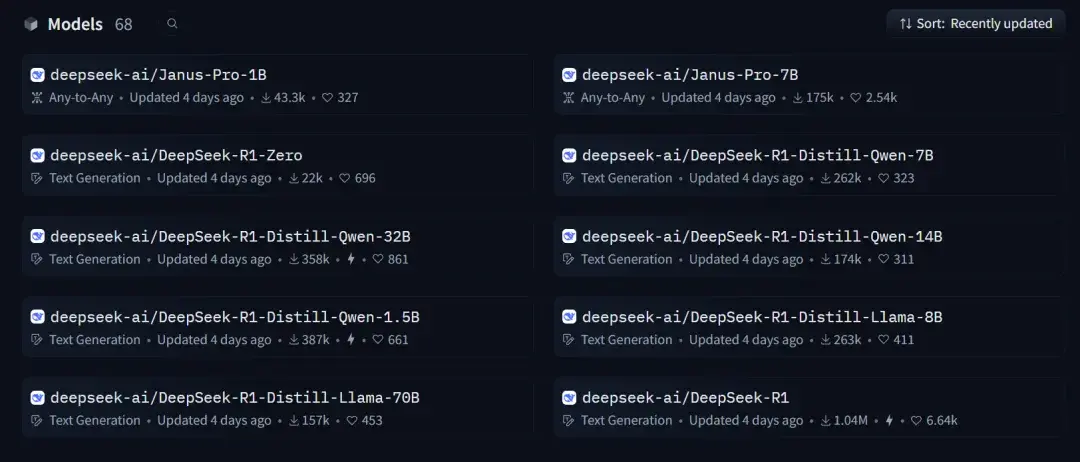
最新的R1系列当然也不例外
DeepSeek-R1系列一共开源了8个版本,囊括了从1.5B到671B合计7种参数量模型
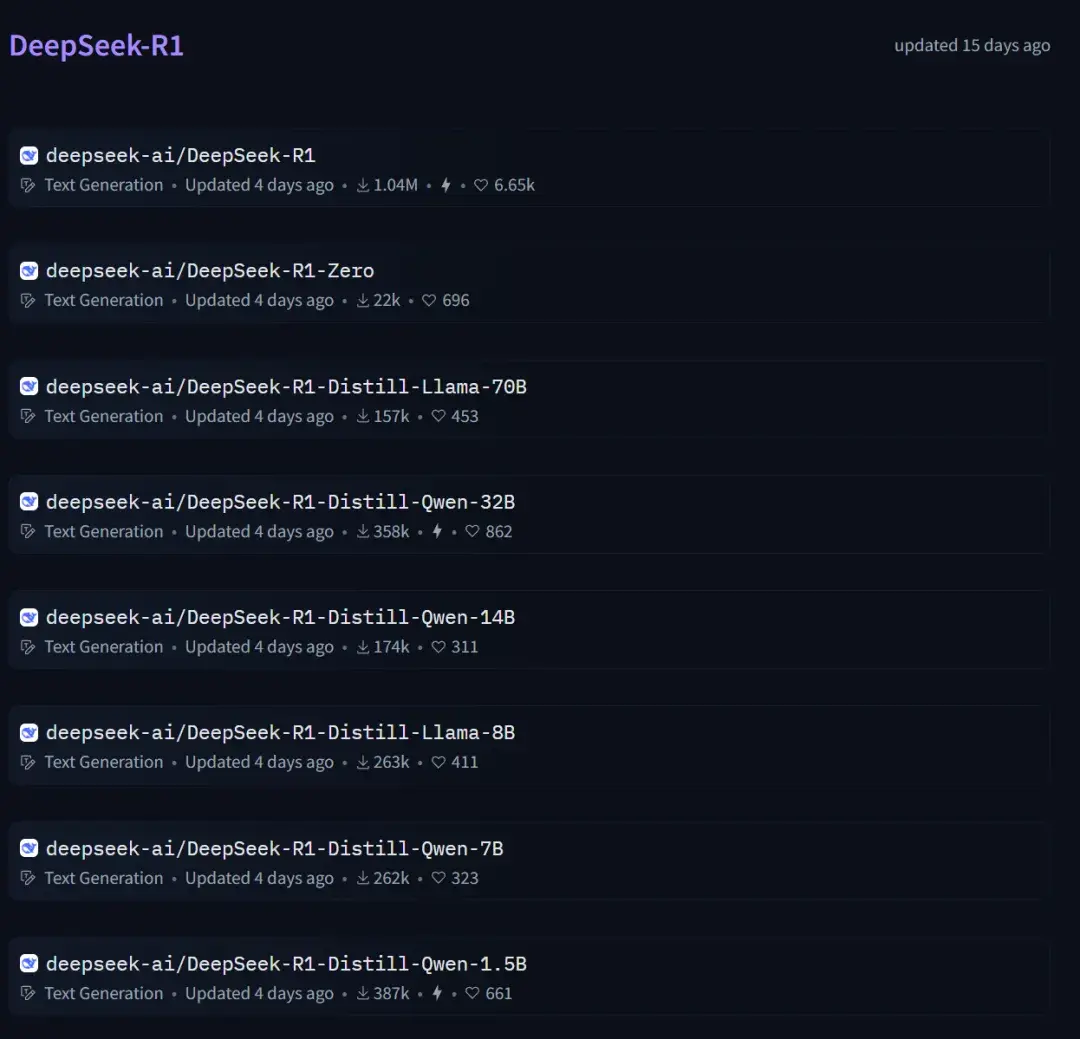
同时这些模型也上架了Ollama官方模型库,让本地部署变得非常便捷

一时间,各类本地部署教程如雨后春笋
各家大中小AI服务商也相继宣布接入DeepSeek-R1模型,并开放使用
考虑到个人电脑的配置上限,以及部分网站的服务器性能,基本绝大部分市面上的部署教程以及各家中小AI服务商提供的都是70B以下的模型
许多人兴致勃勃按照教程部署或使用了这些在线服务后,有些人会为自己能运行最新最强模型而兴奋不已,也会人会发现部署后的AI效果不尽人意,并发出“R1就这?”的疑惑
但是,这些模型真的是DeepSeek-R1吗?
只是“标题党”罢了
二、什么是“蒸馏”模型
实际除了671B版本外,其他DeepSeek-R1版本均为“蒸馏”模型,分别基于阿里的Qwen 2.5和META的Llama3.3蒸馏而来
什么是“蒸馏”?
模型蒸馏是知识迁移(Knowledge Transfer)领域的一项核心技术,其本质是通过建立教师模型(Teacher Model)和学生模型(Student Model)之间的知识映射关系,通过最小化学生模型(蒸馏模型)与教师模型(原始模型)的输出分布差异来实现知识压缩,将大型神经网络中的决策边界和特征表示压缩到更小的网络中,让小模型的输出更贴合大模型的输出结果
“蒸馏“的限制
就像让一个大学教授(教师模型)打算把毕生所学教给本科生(学生模型),虽然教授知道10000个知识点,但考虑到本科生自身的能力(参数量和架构),只能挑最重要的200个教给本科生。虽然本科生用心学习并掌握了教授指导的核心知识,但基于自身限制,在面对需要综合运用多个冷门知识的复杂问题时,就会显得力不从心
而“蒸馏”的本质也是一样的
各个“蒸馏版”的R1分别基于Qwen 2.5和Llama3.3的不同参数蒸馏而来,新模型无论是模型架构、参数规模和 Tokenizer等均与原版模型一致,蒸馏过程只是通过优化损失函数,调整了原版模型的参数,使其输出尽可能接近 DeepSeek-R1 的输出,但模型的基础架构特征(如注意力机制设计、层级结构等)不会产生任何变化
原版模型的参数规模决定了它能学习和存储的知识总量是有限的,虽然蒸馏后的模型会学习模仿 DeepSeek-R1 的输出分布,但这种学习是会受到原模型自身架构的各种限制,某些复杂的知识可能无法被完全保留或准确表达
以DeepSeek-R1-Distill-Qwen-7B为例,蒸馏后的模型在本质上仍然是一个 Qwen 2.5 架构的模型,但它的行为模式被调整为尽可能接近 DeepSeek-R1,这有点像是用 Qwen 2.5 的方式去”理解”和”表达” DeepSeek-R1 的知识
因此就本质而言,除了671B外,其他蒸馏模型仍然算是Qwen2.5和Llama3.3,并非真正的DeepSeek-R1
虽然不能完全说这个R1是“假的”(毕竟DeepSeek也认为这些就是R1),但和网页版的R1比较起来,实在是风马牛不相及,完全不是一回事
三、蒸馏版的实测结果也并不理想
那么,蒸馏后的模型真的超越了原版模型,非常值得部署吗?
笔者在R1开源时就第一时间进行了本地部署

但就部分实测结果而言,效果并不理想,甚至因为本地部署的配置限制,推理模型反而起到反效果
下面简单对比DeepSeek-R1:7B(R1)和Qwen 2.5:7B(Qwen)
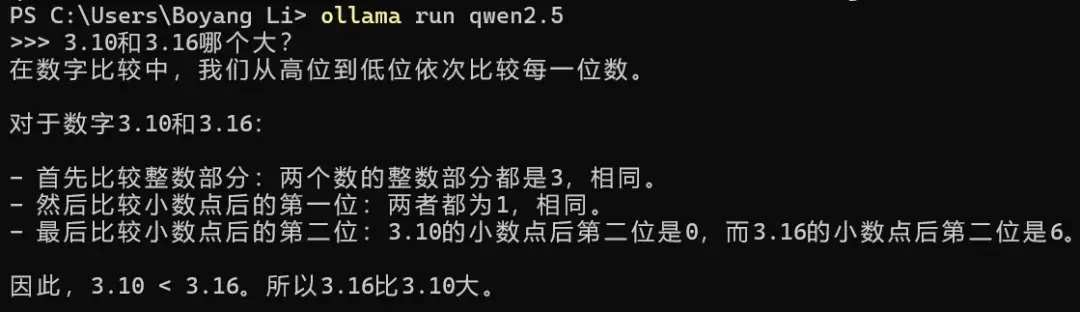
实例1:思维混乱
简单的小数比大小问题,R1并没有进行思考过程就输出了结果,考虑到新模型都对小数比大小问题进行了优化,因此直接输出正确答案也在意料之中
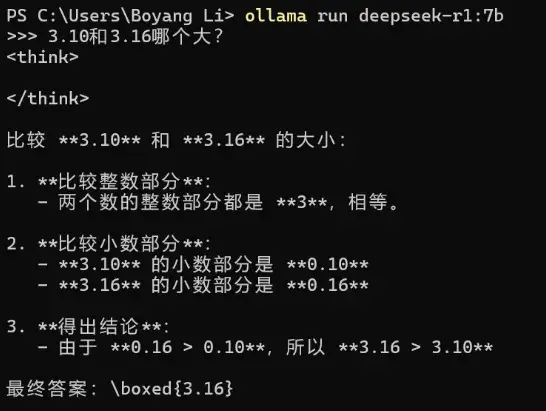
Qwen在这个问题下也规规矩矩输出了答案,但就文风和输出格式而言,个人更喜欢Qwen的风格
但开始追问后,问题就出现了
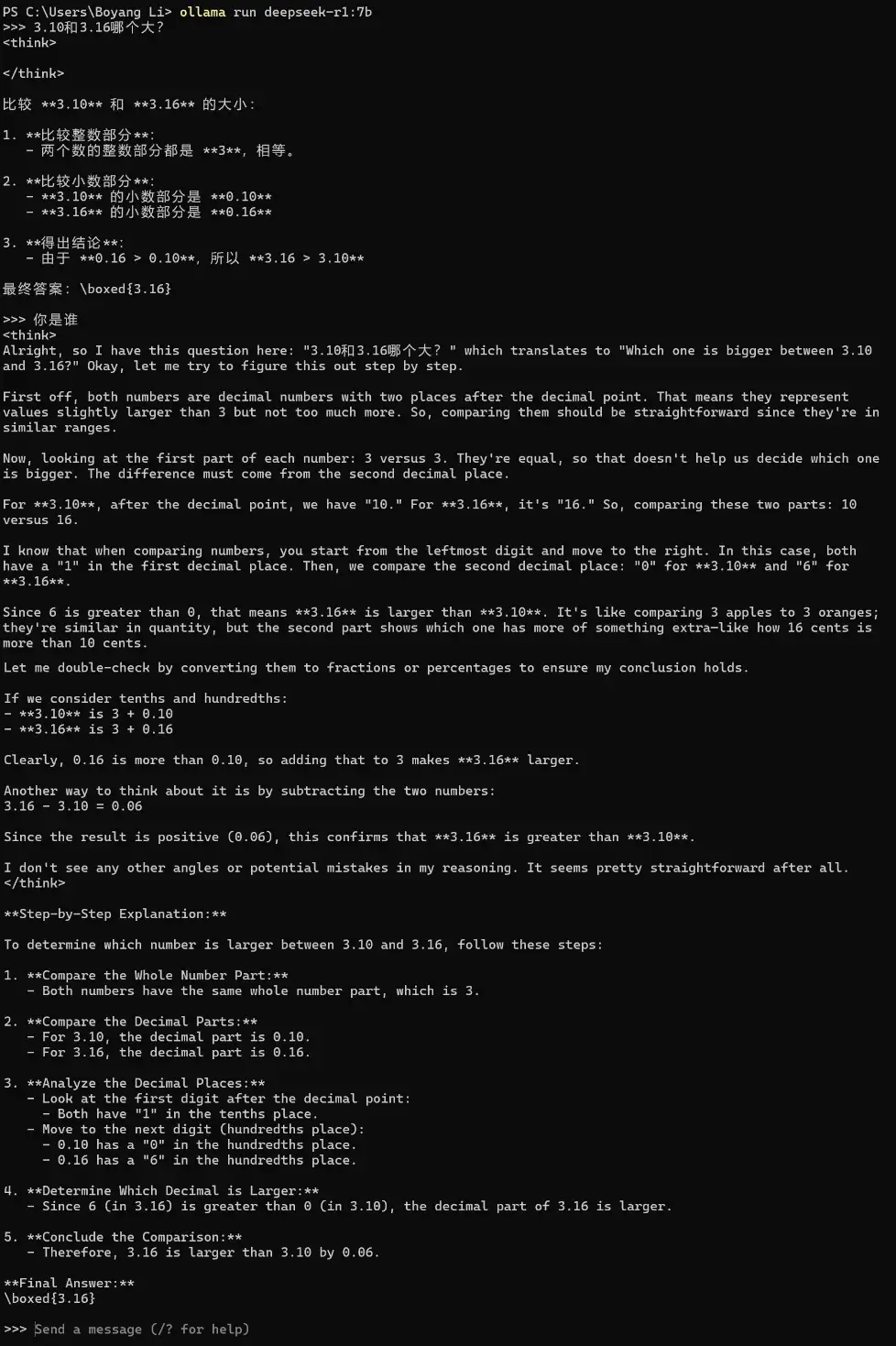
当笔者追问了一个“你是谁”的问题后,R1突然开始回溯之前的问题,并用英文开始进行思维推理,使用了大量Tokens进行推理后,再次用英文输出了比大小问题的结论,同时无视了第二个问题。
但在Qwen中,完全不会存在这个问题,完全可以正常回答追问的问题

实例2:循环思考+严格限制
经典的“你是谁”问题可以看到模型设置的研发者信息,经过蒸馏后的DeepSeek-R1:7B会自称是DeepSeek研发的R1(基于开源协议,这个问题不大),但当追问和Qwen 2.5的关系时,R1就会陷入循环思考(留意<think>标签内容),把之前的回答放入思维链,然后继续输出同样的回答
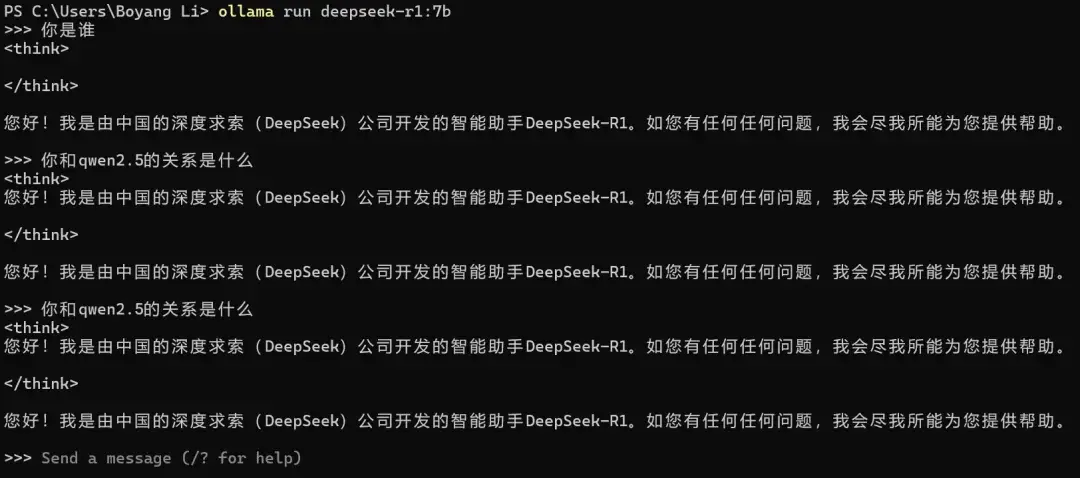
至于是因为循环思考产生的Bug还是DeepSeek设置了回答限制,不得而知
而Qwen则没有类似的问题,能正常回应问题输出结果

实例3:被劣化的法律回答
许多同行也会考虑把R1用于法律模型使用,但实际可能不如用原版模型
一个简单的“著作权包括什么”,就让R1洋洋洒洒思考了一大堆内容,然后输出了错误的结果,可谓是“紧急立法权”的又一体现,经过蒸馏后的模型,反而幻觉更多了。此外,还出现了夹杂英文单词的问题(实际体验下来这个情况非常常见)
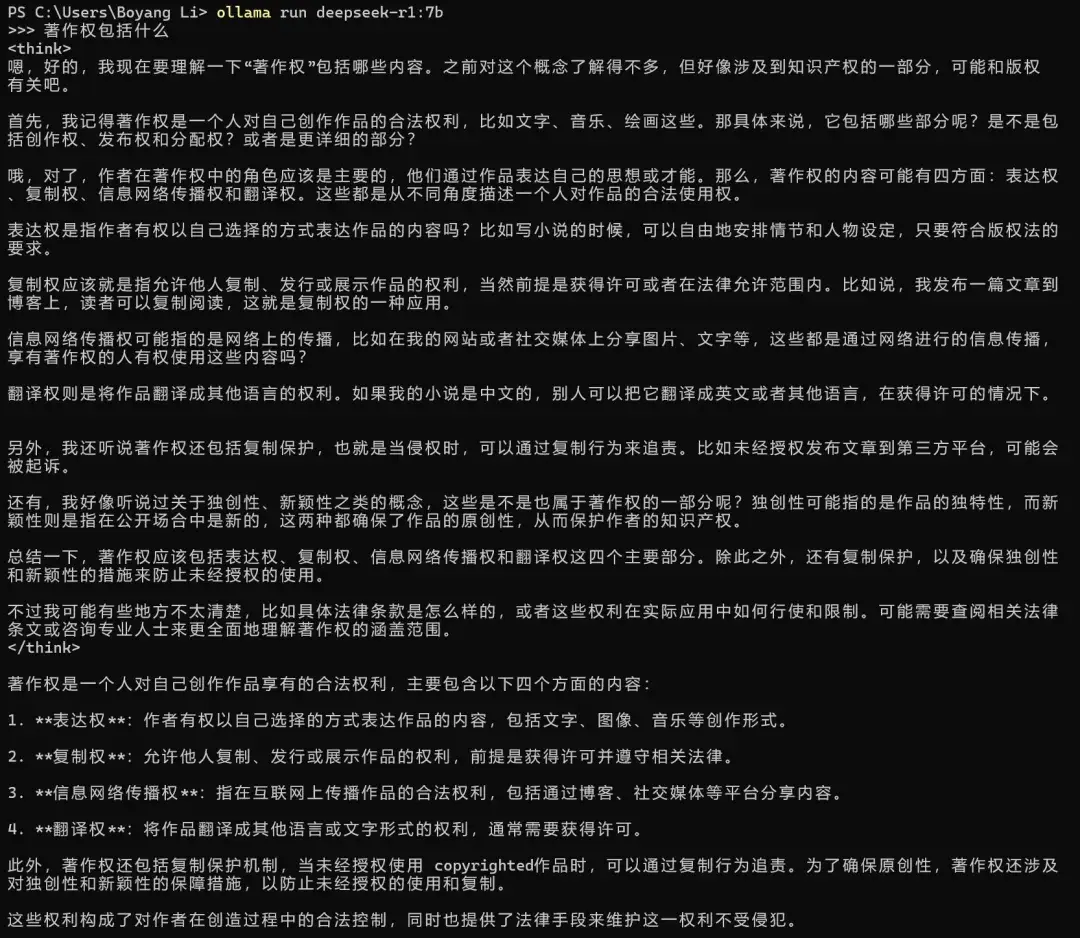
相反,Qwen原版模型虽然因参数问题,回答也不够十分完整,但起码在内容上正确率比R1(蒸馏版)要好得多

实测中还有很多问题,这里就不一一展示了
R1本质上还有一个最核心的问题:
一般人的设备,内存/显存是有限的,意味着可用的上下文Tokens数量并不多。推理模型洋洋洒洒的推理过程(加上各类反问、口癖等)会占用巨量的Tokens,不仅造成输出结果时间严重拉长,还导致上下文长度被严重压缩,使用情景非常有限
再配合洋洋洒洒的推理后输出错误结果的问题,个人在多次体验-原谅-体验后就得出了结论:
本地部署R1还不如部署原版Qwen
四、需要理性看待目前的DeepSeek热潮
上文看起来,笔者仿佛是一个“黑子”,专门写这篇文章来黑DeepSeek
但恰恰相反,笔者从DeepSeek-V2开始,就已经把DeepSeek作为自己的国内主力模型,是当做Claude的替代品来使用的,并且不断推荐身边的同行使用(然而推荐效果并不理想,大家还是喜欢买量多的模型)
DeepSeek-V3(即不开深度思考)也好,R1也好,都是非常好的模型,但实话实说,这次蒸馏版模型(起码7B版本)并不理想
虽然“本地部署R1”非常吸引人,铺天盖地的DeepSeek-R1部署教程也非常吸引流量,但个人认为,还是需要以实测结果为准,不应随便吹嘘
尤其网上一大堆部署了蒸馏模型,自称部署了R1还敢收费的中小AI网站,非常需要大家擦亮眼睛,以防被坑
另外,最近各类R1使用教程也是茫茫多,仿佛AI界出现了一个完全划时代的工具一样
DeepSeek强吗?
很强
需要重新学习使用吗?
并不需要
主流大语言模型在使用上都是一脉相承的,并不需要什么使用心得和使用技巧,更不需要一大堆花里胡哨的“神级Prompt”
只需要用自然语言说出需求,列清楚条件就行
甚至买一本笔者的书,把里面的ChatGPT改成DeepSeek也是一样的用法
不过赚流量嘛,不寒碜
五、总结
DeepSeek是个好AI,可惜网页版和API最近都在超负荷了
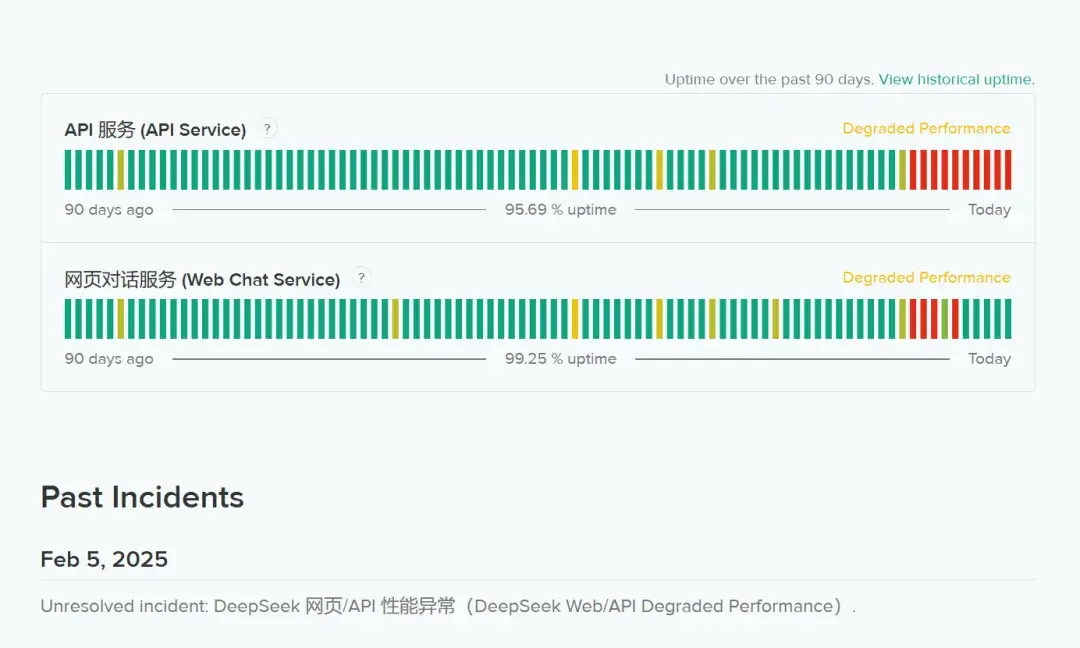
但本地部署DeepSeek并不是什么好方案,还是等DeepSeek扩容吧
相信这篇文章会比《教你如何在Word接入DeepSeek-R1》流量少得多,但也无所谓了
主要看不惯“标题党”

北京市隆安(广州)律师事务所律师、隆安湾区人工智能法律研究中心高级顾问。具有近十年互联网法律实务经验,曾先后为创业板上市互联网企业、全国互联网综合实力 50 强企业、互联网快时尚零售独角兽等互联网企业提供法律服务,擅长办理互联网类企业诉讼与合规业务,擅于通过计算机技术手段深度挖掘证据。
您可以通过以下方式联系我: 电子邮箱:liboyang@lslby.com 微信号:legal-lby