I Trained a Better Legal Embedding Model Than Google and Alibaba?
Sharing the complete process of fine-tuning a legal-specific embedding model: based on Google's EmbeddingGemma-300M, trained on a legal provision-to-colloquial question dataset, outperforming Google and Alibaba's models in legal provision retrieval, now open-sourced.
A while ago, I built a legal provision lookup tool.
I initially made it for personal use, but since I’d already built it, I decided to share it:
While using it, I felt the legal provision recall wasn’t good enough. So I looked at my GPU and thought:
“Why not fine-tune my own model?”
Note: This is an Embedding model, not an LLM — it cannot be used for conversation.
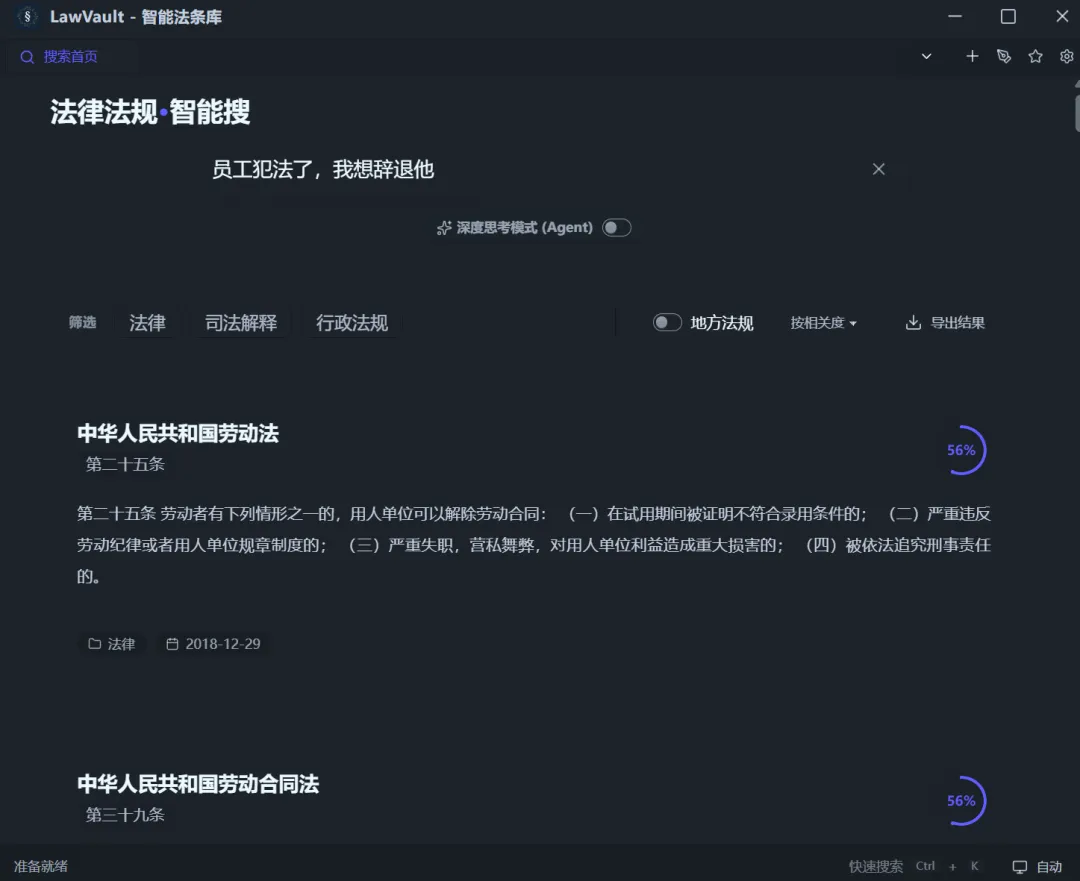
1. Results
Models Compared
Original embedding model: Google’s EmbeddingGemma-300M
Excellent domestic embedding model: Alibaba’s Qwen3-embedding-0.6b
Both are excellent lightweight embedding models, ranking highly on the global open-source embedding model leaderboard, and suitable for most hardware.
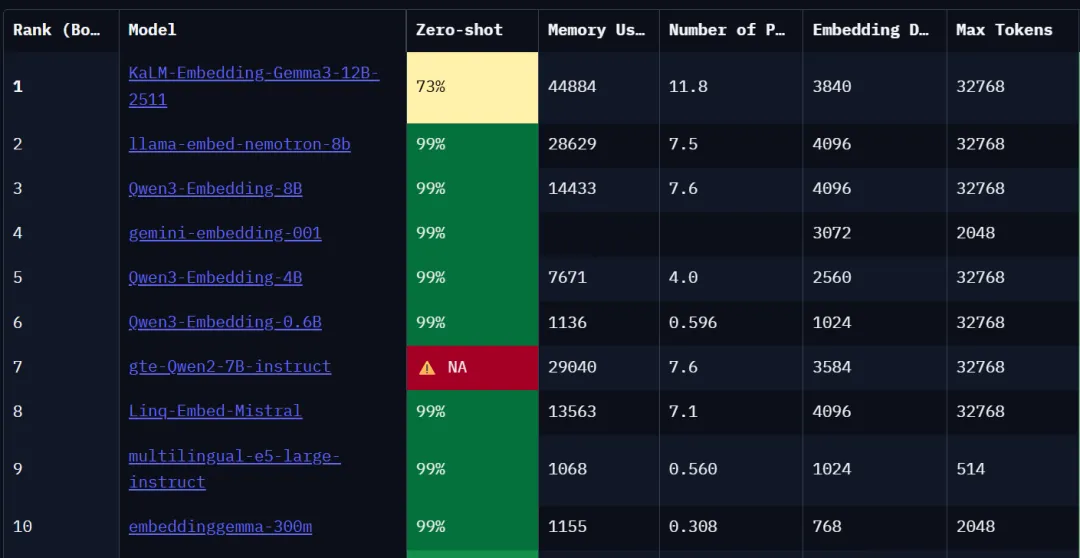
That’s why I initially chose EmbeddingGemma-300M as the base model for the legal provision database.
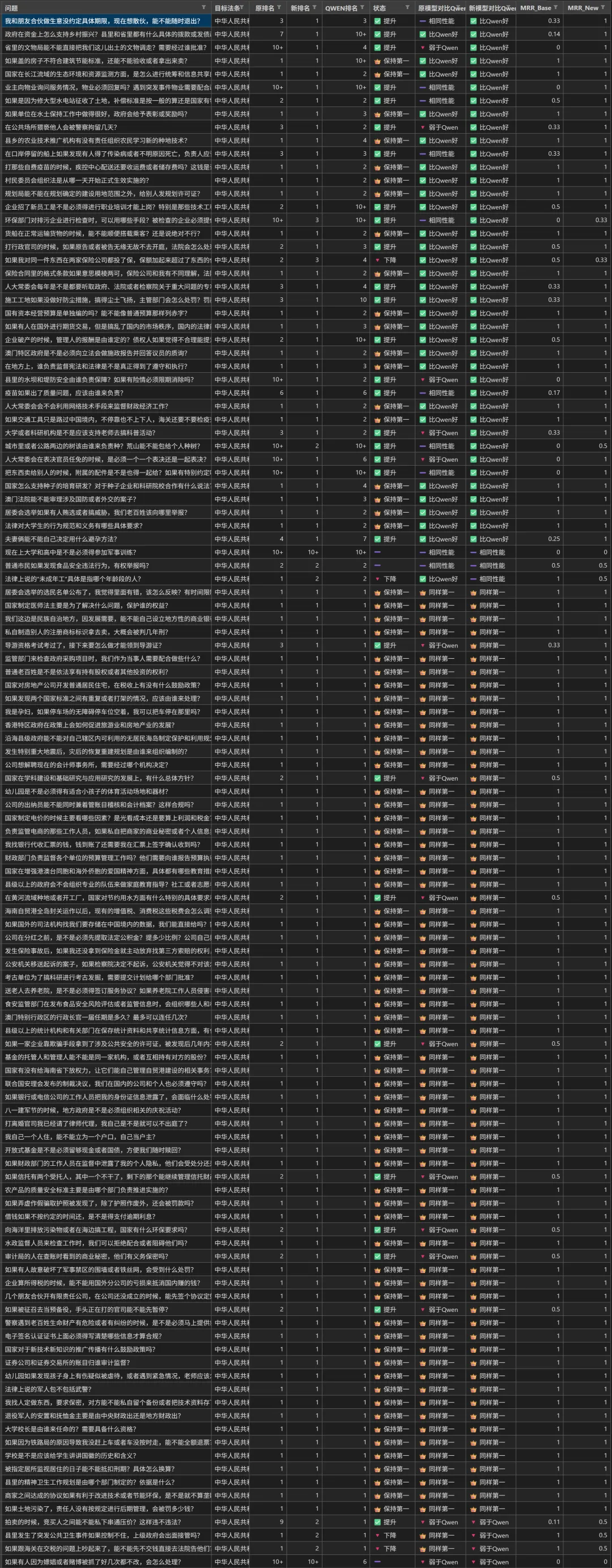
Comparison Results
The comparison process: randomly select over 100 legal provisions from the database, have Deepseek generate colloquial questions based on each provision (similar to ordinary user queries), then compare each model’s ranking of the target provision among all retrieved results.
After fine-tuning, the results are shown below (long image warning). Over 1/3 of the retrieval results outperformed Alibaba’s Qwen3-embedding-0.6b model; compared to the original Google EmbeddingGemma-300M, over 1/4 of the retrieval results improved in ranking:
2. Open Experience
Fully Open
The trained model has been uploaded to Ollama, ModelScope, and HuggingFace.
Ollama users can pull it with:
ollama pull demonbyron/embeddinggemma-300m-lawvaultNote: This is the bf16 quantized version.
ModelScope page:
https://modelscope.cn/models/ByronLeeee/EmbeddingGemma-300M-LawVault
HuggingFace page:
https://huggingface.co/ByronLeeee/EmbeddingGemma-300M-LawVault
How to Use
To use it with LawVault, you must update the legal database file, otherwise it won’t return correct provisions.
Download the new vector database file package from:
https://pan.xunlei.com/s/VOgpB1Qqjfe8uxRokBXzyy-BA1#
Then delete the original vector database folder (law_db.lancedb) and extract the new database folder in its place (no need to delete the content.db file).
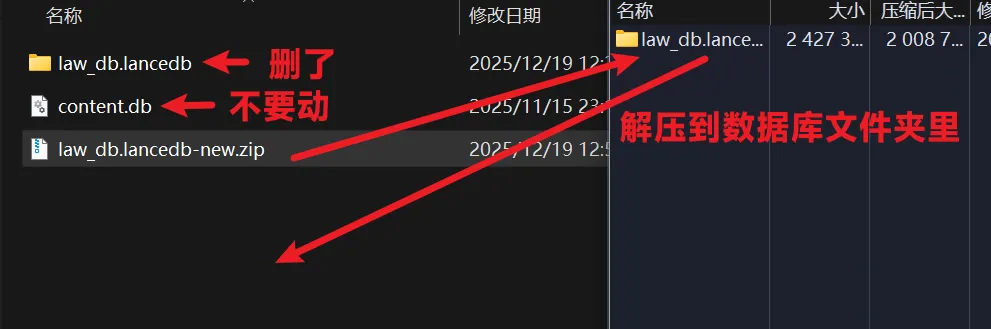
In the settings, change the model name to:
demonbyron/embeddinggemma-300m-lawvault:latest
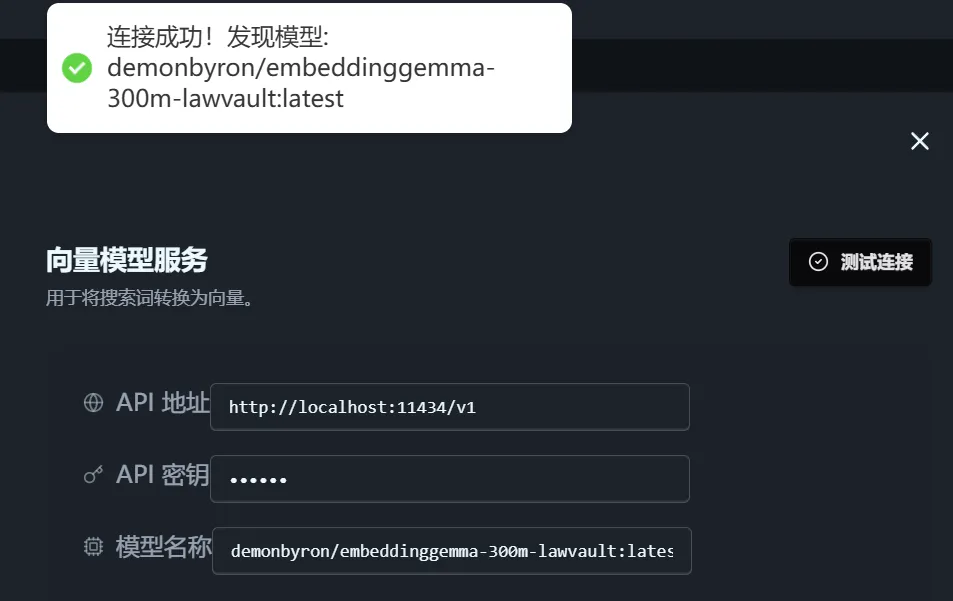
Then just ask questions normally:
New Features
Compared to the previous version, several new features have been added — welcome to try them:
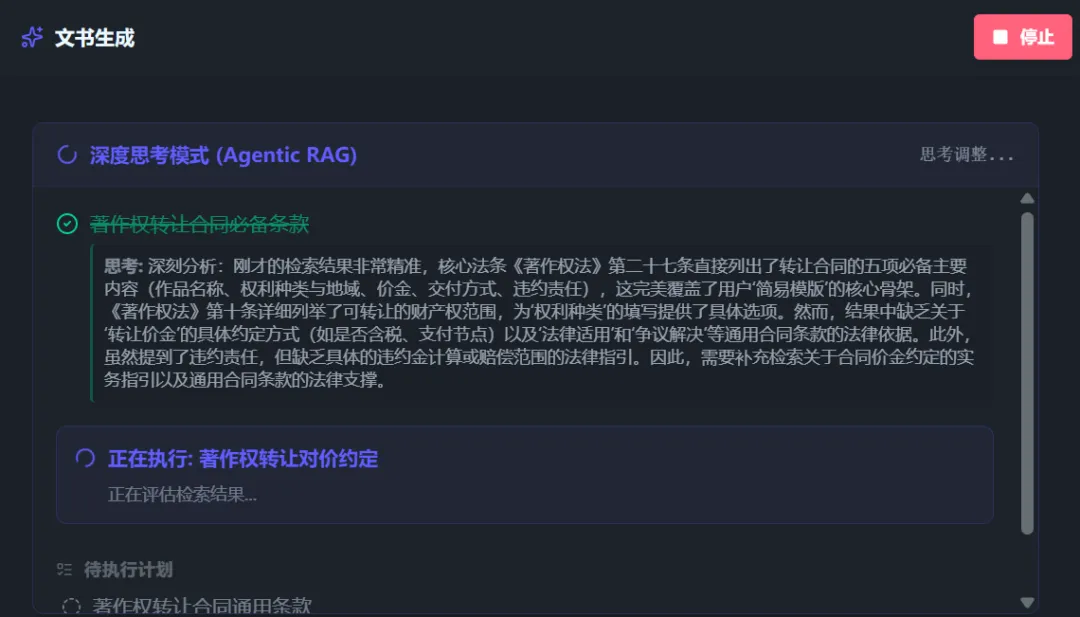
【Legal Provision Search Agent】
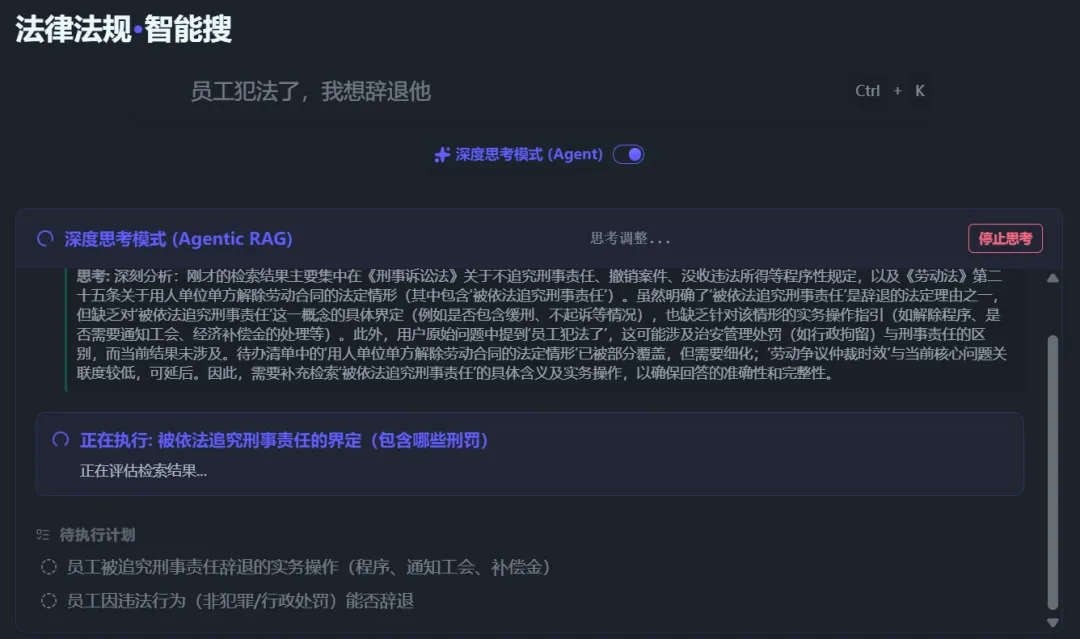
After enabling 【Deep Thinking Mode】 and 【AI Q&A】, AI will first break down the search question, list multiple search directions, and automatically perform searches.
The agent automatically determines whether the search results are sufficient to answer the question. If not, it continues searching for subsequent questions or adds new keywords.
When AI determines the search is complete (or has reached the maximum search rounds), it will consolidate all retrieved provisions and generate a search report based on the question:

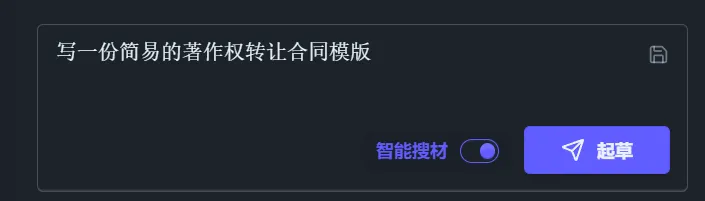
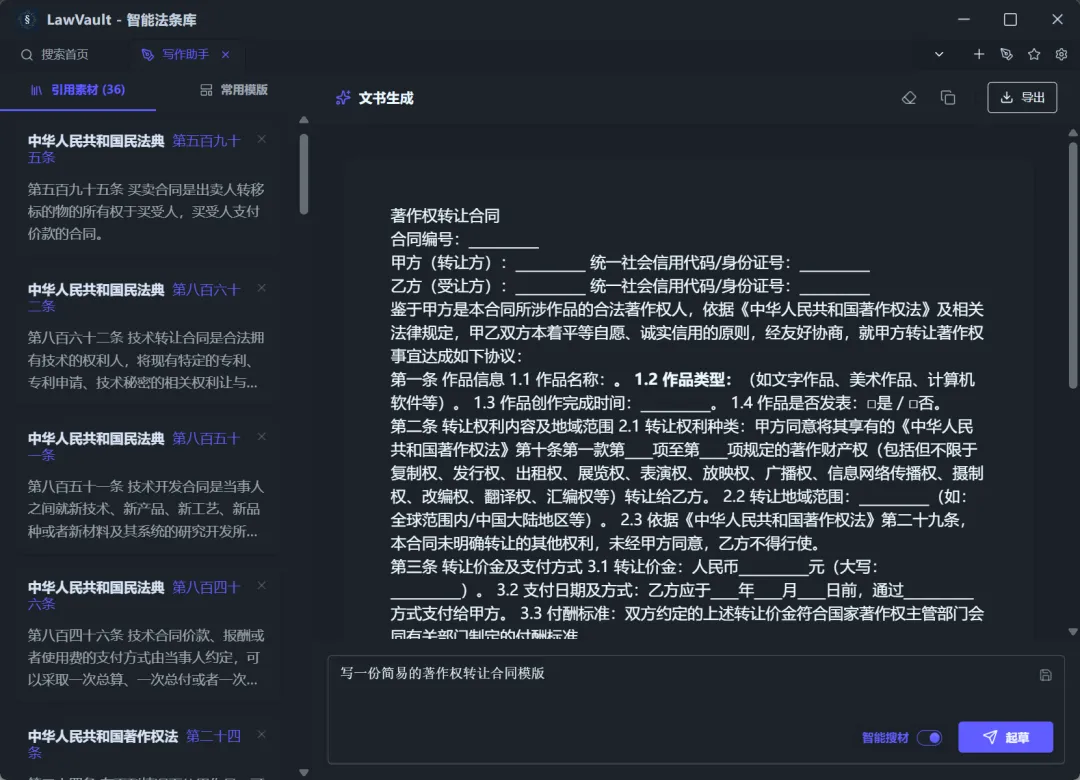
【Writing Assistant】
You can now add retrieved provisions or full-text selections directly to the material library, and use the writing assistant to have AI draft the required text content.
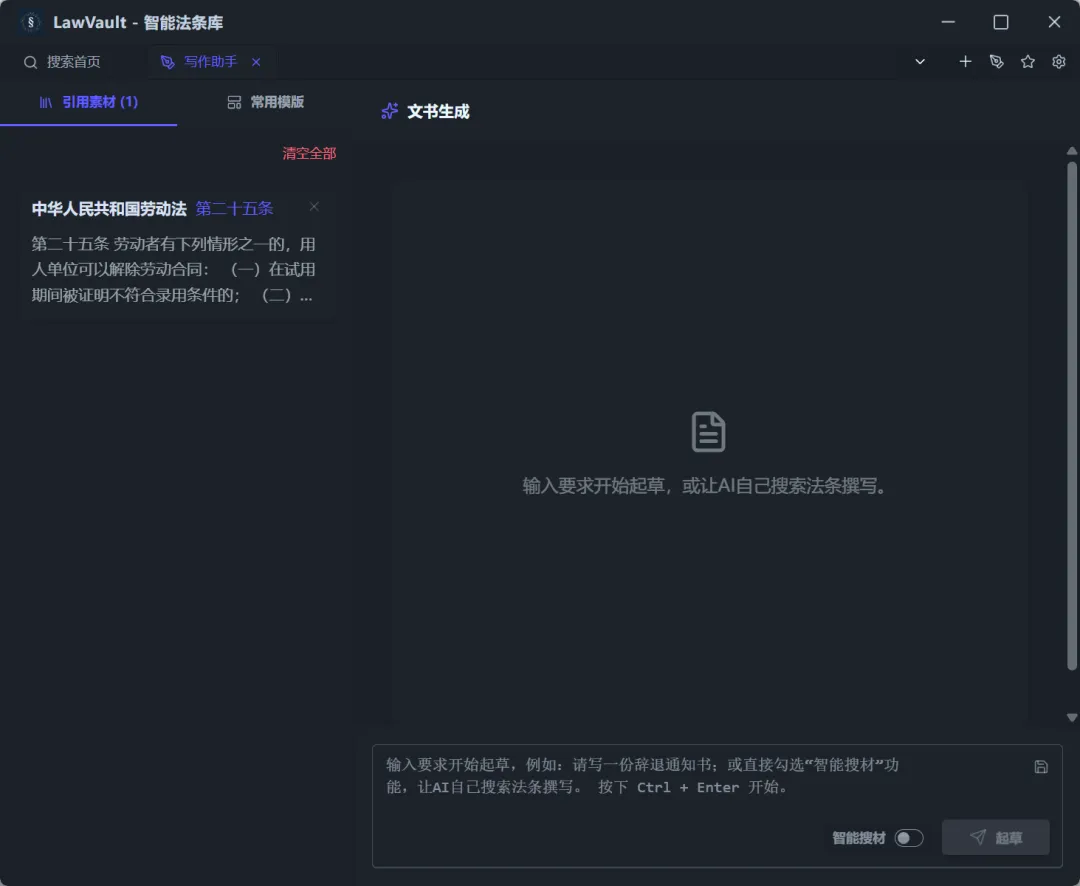
You can also use the “Smart Material Search” feature to let AI search for the required provisions and draft content:
Supports various export formats — for example, copy directly formatted for use in Word:

3. Principles and Fine-Tuning Process
This is the dry technical section. If you’re not interested, feel free to share and like this article before closing. Thank you!
Embedding Principle
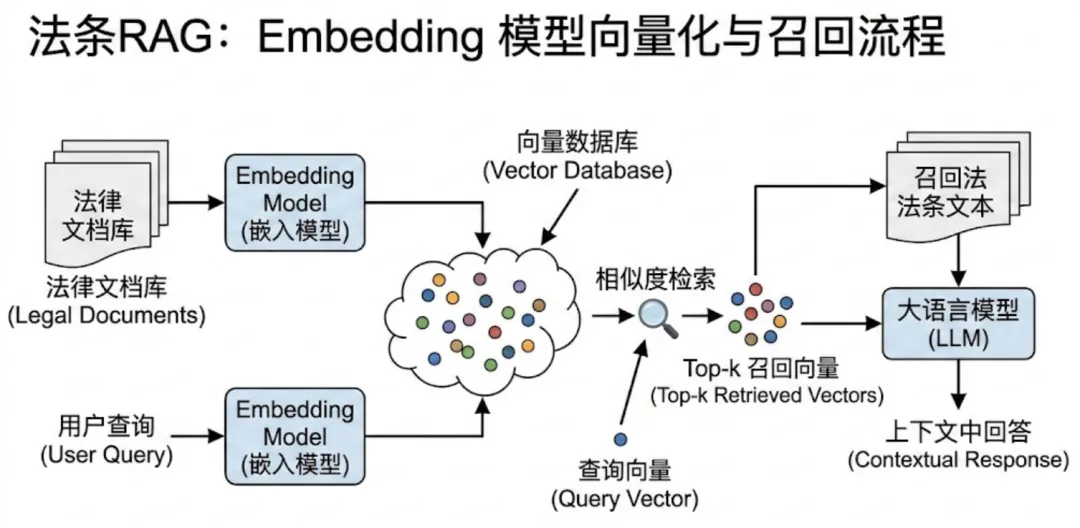
The legal provision RAG workflow is shown above.
Why do many legal databases struggle to find the right provisions?
Because vector search performs text similarity search.
This means the search content must have high similarity to the “legal language” of the provision text to successfully return the correct provision.
So there’s a paradox:
Only if “I” already know the content of the provision can “I” search for it;
But if “I” already know the provision, why would “I” need to search?
Fine-Tuning Process
So I decided to try fine-tuning the embedding model.
First, I took over 20,000 already-split legal provisions (pure laws, excluding judicial interpretations and local regulations) and used the Deepseek V3.2 model to generate colloquial questions based on each provision.
Each provision was queried in 3 different tones, ultimately generating 65,783 question-answer pairs.


Since EmbeddingGemma (and embedding models in general) are best fine-tuned using triplet format (query, positive example, negative example), and generating negative examples via LLM might be unstable, I ultimately used:
The closest provision in the original model’s vector database (excluding the target provision) returned for the training question
as the negative example, completing the full training dataset.
Then came routine training. Parameters:
Batch size: 24 (effective batch size = 144, gradient accumulation)
| Epoch | Step | Training Loss |
|---|---|---|
| 0.0022 | 1 | 3.5148 |
| … | … | … |
| 1 | 457 | 0.2123 |
| 2 | 914 | 0.0749 |
| 3 | 1371 | 0.0369 |
Training on an RTX 5070 Ti 16G, 3 epochs took about 2.5 hours — acceptable speed overall.
4. Finally
The title is a bit “clickbaity.”
After all, the fine-tuned model only has an advantage in the specific scenario of correlating colloquial legal questions with specific provisions.
But what I want to show is that model fine-tuning is actually very accessible.
The models provided by major companies are usually “common denominators.” Fine-tuning a model for your own use can further improve model utilization.
I believe the future will inevitably involve a combination of local personalized small models and online large models. Having your own model is definitely satisfying.
