The Algorithm Model Should Be the Core of Artificial Intelligence (AI) Infringement Review — Taking Diffusion Model and Algorithm as Examples
Argues that AI copyright infringement review should center on the algorithm model's working principles, using Stable Diffusion's diffusion model to show that normally generated outputs reflect learned commonality rather than copying specific training works.
I. Introduction
The rapid development and widespread application of artificial intelligence (AI) technology are profoundly changing human production methods and lifestyles. In the field of cultural creativity, AI technology is also widely used in music, painting, literature, and other creative fields. For example, AI-generated music, paintings, and literary works have been publicly displayed and even appeared at auctions. However, AI technology also brings challenges to intellectual property protection. Unlike traditional cultural and creative fields, works generated by AI technology involve complex technical algorithms behind them. From the training of AI technology to the final generation of works, the use of various algorithms is essential. How to determine whether AI-generated content (AIGC) based on these algorithms involves intellectual property infringement has become an urgent problem to be solved.
This article will start from the perspective of machine learning algorithm models, exploring how to review whether content generated by AI technology infringes copyright. Using the AI image generation software Stable Diffusion, which employs the Diffusion model and algorithm, as an example, this article discusses the importance of “taking machine learning algorithm models as the core for judging AI work infringement,” providing ideas and references for determining whether AI works infringe intellectual property rights. In addition, this article will only discuss the basic implementation principles of algorithms and models, and will not study their specific implementation methods or mathematical formulas.
II. History of AI-Generated Images
Since the 1950s, computer graphics has been one of the key research areas in artificial intelligence. With the continuous upgrading of computer hardware and the rapid development of deep learning algorithms, people began to explore how to use AI technology to generate images. In the early 1990s, people began using rule-based methods to generate simple geometric shapes, including fractal images and L-systems. However, these methods could only generate basic geometric shapes, not complex images. It was not until the early 21st century that people began attempting machine learning-based methods to generate images, and the concept of “AI-generated images” entered the public eye.
The important history of AI-generated images since the 21st century can be roughly divided into the following stages:
1. The Dawn Brought by Deep Learning
In 2006, Geoffrey Hinton and his students invented an engineering method using computer graphics cards (GPUs) to optimize deep neural networks, and published papers in Science and related journals. This was the first time the new concept of “Deep Learning” appeared in people’s view. They leveraged the parallel computing power of GPUs to distribute the computational tasks of neural networks across multiple processing units for parallel processing, thereby accelerating the training and inference process of neural networks. This method greatly improved the computational speed of neural networks, laying the foundation for the development of deep learning, while also reducing the computational cost and time cost of AI-generated images to an “acceptable” level.
 Geoffrey Hinton and his two newly graduated students — Alex Krizhevsky and Ilya Sutskever
Geoffrey Hinton and his two newly graduated students — Alex Krizhevsky and Ilya Sutskever
2. The Autoencoder Era
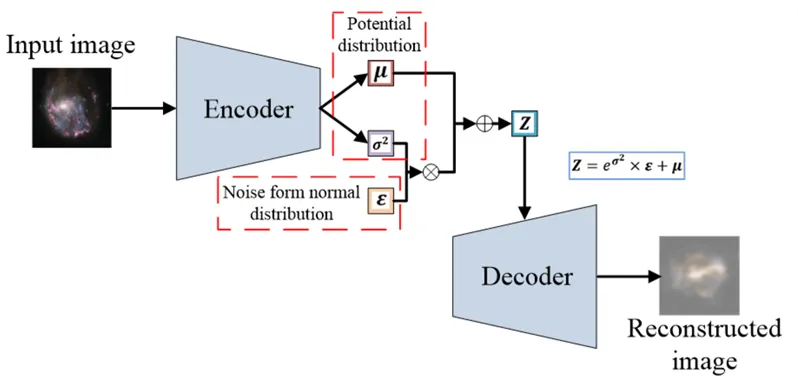
In the mid-2010s, with the development of deep neural networks, several text-to-image models based on autoencoders (AE) and variational autoencoders (VAE) emerged. They were typically used in unsupervised learning scenarios, learning features and representations of images from large amounts of image data without explicit image labels or annotations. An autoencoder is a neural network model consisting of an encoder and a decoder. The encoder compresses input data into a low-dimensional vector, and the decoder restores that vector to the original data. In the task of text-to-image generation, the input data can be a text description, the encoder compresses it into a vector, and the decoder restores that vector into an image. A variational autoencoder is an improved model based on the autoencoder that can not only compress input data but also generate new data. VAE introduces a latent variable in the encoder to represent the potential features of the input data, such as color, texture, and shape. The decoder generates new data through the latent variable. In the text-to-image task, the latent variable can represent the style or features of the image, and the decoder can generate different images based on different latent variables.
3. GAN — The Master of Left-Right Sparring
In 2014, Goodfellow et al. proposed Generative Adversarial Networks (GAN), ushering in a new era. A GAN consists of a generator and a discriminator. The generator receives a random noise vector as input and generates an image. The discriminator receives an image (which could be a real image or a “fake” image generated by the generator) as input and outputs a value indicating whether the image is real or generated. The generator and discriminator improve their performance through adversarial training. The goal of the generator is to generate as realistic images as possible, while the goal of the discriminator is to distinguish real images from generated images as accurately as possible. During training, the generator and discriminator compete with each other, continuously adjusting their parameters until the generator can generate sufficiently realistic images that the discriminator cannot distinguish between real and generated images. After training is complete, the generator can receive any text as input and generate images related to that text. Through adversarial training, the generator can learn how to extract key information from text and convert it into images. This method can be used to generate various types of images, such as landscapes, people, animals, etc. Through adversarial training, GAN can produce high-quality and diverse images. After 2016, a series of GAN-based text-to-image models emerged, such as Stack-GAN, Attn-GAN, and Big-GAN. These models introduced techniques such as attention mechanisms, hierarchical structures, and conditional information to improve the alignment and refinement of text-to-image generation.
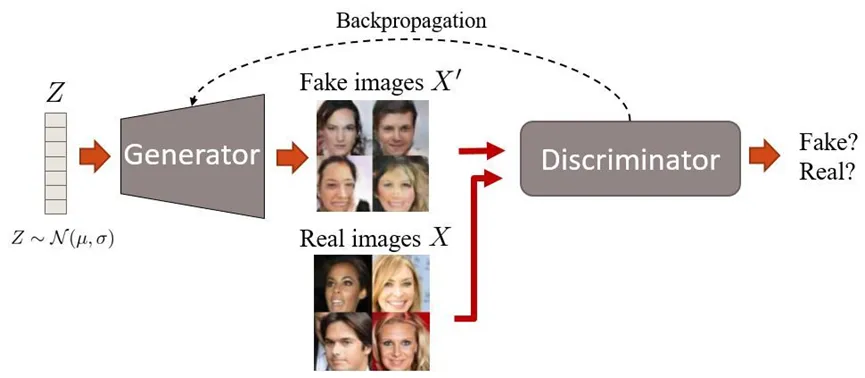 Simple example of the principle of Generative Adversarial Networks (GAN)
Simple example of the principle of Generative Adversarial Networks (GAN)
4. DALL-E Ushered in the Era of Ultra-Large Data Models
In early 2021, the OpenAI Foundation released an AI model based on a 12-billion-parameter version of GPT-3 as its core algorithm: DALL-E. DALL-E uses a VQ-VAE, which is a variational autoencoder that can discretize images into tokens. It uses a Transformer to jointly encode text and tokens, and trains using an autoregressive loss function. Simply put, DALL-E’s training dataset contains various images and their corresponding descriptive texts, such as “a yellow cat sitting on the grass” and “a red firebird flying in the sky.” By learning the relationships between these images and texts, the model can generate images that match the given text description. When generating an image, DALL-E first converts the text description into a vector representation, then concatenates it with a random noise vector to obtain an input vector. Next, the model converts the input vector into an image through multiple layers of convolutional neural networks and deconvolutional neural networks. During this process, the model improves the quality and diversity of the generated images by minimizing the reconstruction error.
5. Diffusion Models Lead the AI Image Generation Craze
Starting in the second half of 2021, after the OpenAI Foundation released the GLIDE text-to-image model using the Diffusion Model, it sparked a new wave in the field of AI-generated images. Subsequently, the Midjourney platform launched an online text-to-image service (currently version V5.1) through its official Discord bot, Stable Diffusion software provided a text-to-image toolbox based on the diffusion model, and OpenAI officially opened DALL-E 2.0’s text-to-image functionality. Since then, AI image generation software has formed a tripartite balance. Especially when Stability AI officially open-sourced the Stable Diffusion program and model online, anyone could use their own computer or network server to build a painting application and generate any image they desired.
The craze for AI painting discussions in China also originated from this. Considering that, currently and for the foreseeable future, the diffusion algorithm-based Stable Diffusion will be the mainstream civilian AI image generation algorithm, this article will use this software and its algorithm as an example to discuss related legal issues.
III. Principles of Image Generation by Diffusion Models
1. Relationship between Model and Algorithm
Before explaining the principles of the diffusion model, I would like to introduce the relationship between “model” and “algorithm” in machine learning concepts.
In machine learning, algorithms and models are two important concepts. An algorithm refers to a process run on data to create a machine learning model. Machine learning algorithms can “learn” from data or “fit” a model to a dataset. In machine learning, there are many different algorithms, such as classification algorithms, regression algorithms, and clustering algorithms.
Once a machine learning algorithm completes training, it generates a machine learning model that represents what the algorithm learned from the data, including rules, numbers, and other algorithm-specific data structures used for making predictions. A machine learning model can be viewed as a “program” that contains data and the processes for using that data to make predictions. For training data, we generate a model by running a machine learning algorithm and save it for future use in predicting new data.
Simply put, the algorithm is the process used to generate the model, while the model is the output result of the algorithm. When using machine learning for tasks, we typically choose an appropriate algorithm to generate a model that can make predictions on new data. By continuously applying machine learning algorithms, we can continuously improve and optimize the generated model to better solve various real-world problems. [1]
In machine learning, the process of generating a model through algorithms can be summarized in the following steps:
-
Data collection: Collect the dataset used for training the model. In the context of image generation, the dataset consists of various images collected based on model requirements.
-
Data preprocessing: Clean, transform, standardize, and label the data so that the algorithm can better understand and process the data.
-
Algorithm selection: Choose a machine learning algorithm suitable for the current task. This typically involves considering the algorithm’s accuracy, speed, complexity, and interpretability.
-
Model training: Train the model on the dataset using the selected algorithm. The algorithm learns from the data’s features and labels and generates model parameters such as weights and biases.
-
Model evaluation: Use evaluation metrics to assess the model’s performance on new data.
-
Model deployment: Use the trained model to make predictions or classifications on new data.
The entire training process can be illustrated in the following diagram:
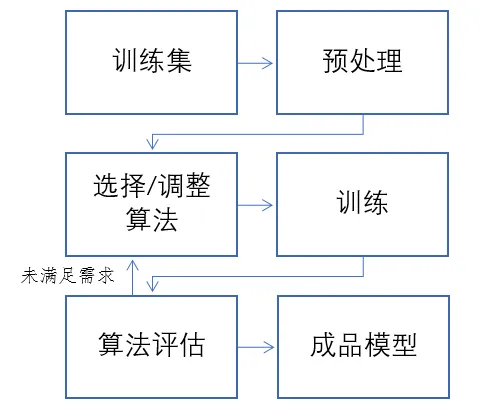
In this flowchart, the algorithm is used to process data and generate a model, and is also used to check whether the model meets the expected output results. The algorithm is the core of the model, and the model is the result of the algorithm.
2. Principles of the Diffusion Algorithm
The diffusion algorithm is a generative model that can be used to generate data such as images, text, and audio. Its basic idea is to add noise to real data, making it gradually random, and then use a denoising network to reversely reconstruct the original data.
Like other AIGC algorithms, the diffusion algorithm also has training and sampling (generation) processes. Both training and sampling are based on the Diffusion Process and the Denoising Network. The diffusion process involves adding continuously increasing Gaussian noise to real data, gradually turning it into random noise. The denoising network is a neural network that can recover the original data or clearer data from the already noise-added data based on the current noise level.
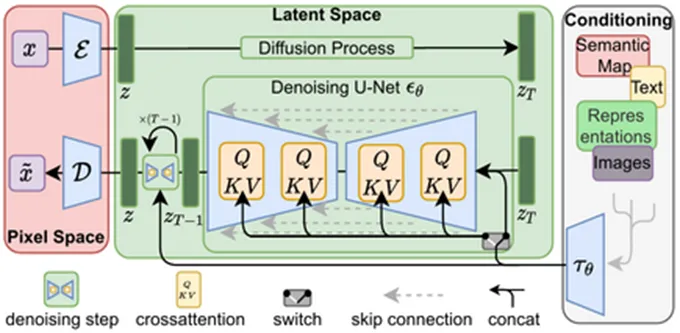
During training, different levels of noise are added to the real data, and then the denoising network is used to predict the original data or the next step’s data. A loss function measures the difference between the prediction and the true value. The training goal is to enable the denoising network to recover the original data as well as possible at any noise level.
In layman’s terms, it’s like gradually adding random noise to an image until it becomes a completely noisy image, and then using a denoising network to restore the noisy image back to a normal image by randomly adding pixels. The denoising network records the random values of the noise and uses “predictive adjustment” to determine how to “add pixels” to better match the “style” of the original training material.
When there is enough training, the model containing this “prediction algorithm” is officially completed. If you could “open up” this model, you would find that it contains a large number of “prediction paths” showing “how to turn a noisy image into a normal image.” The program can follow these “paths” to generate various images that match the style.
When generating images, it starts from random noise, then uses the denoising network to gradually reduce the noise level and predict the direction of the next reduction (following the previously learned “paths”), generating clearer data. Ultimately, when the noise level reaches zero, we obtain the generated data.
 Example of the generation process; the training process can be seen as the reverse of the generation process
Example of the generation process; the training process can be seen as the reverse of the generation process
3. Using Keywords (Prompts) to Generate Specific AI Images
In the original diffusion model, even a well-trained model could only aimlessly generate images that conformed to the patterns of the training set. If the training set is filled with different types of images, the final result would “look like everything” but not actually be understandable.
To ensure the output meets our expectations, the AI program needs to introduce a classification and judgment system to determine the final direction of the generated image.
Taking Stable Diffusion V2 as an example.
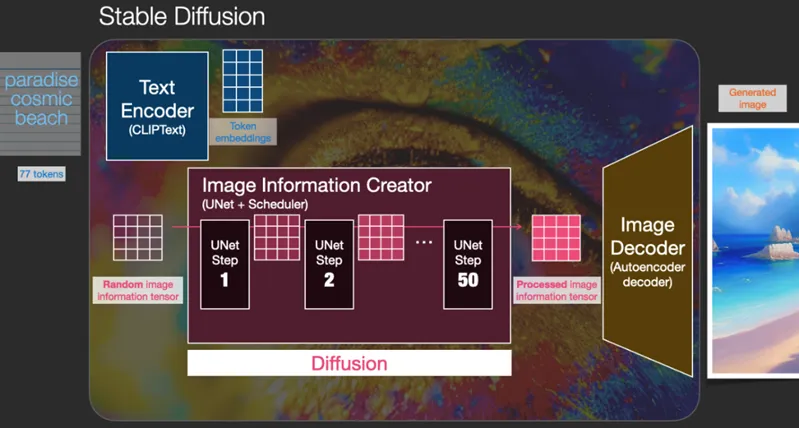
Stable Diffusion introduces a text model called OpenCLIP as a text encoder. This model is trained with up to 350 million parameters (“parameters” can be simply understood as “training data”). Each training instance consists of an image and its description (in practice, these training instances are obtained by “crawling” images and their descriptive texts from the internet, but this article will not discuss the legality of the training set sources).

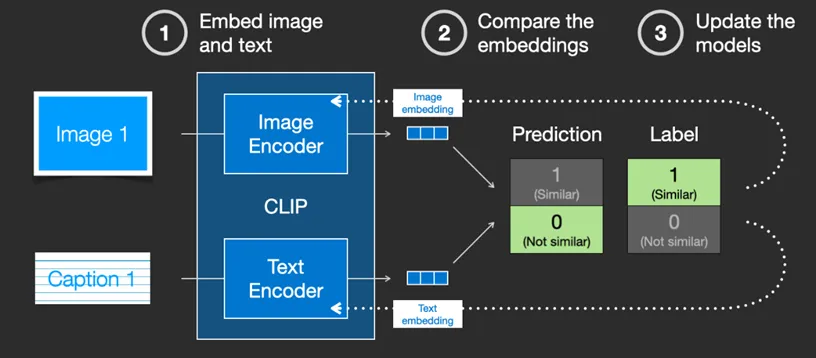
CLIP’s training process can be simplified as “determining whether the text description matches the image.” After encoding both images and text through an image encoder and a text encoder respectively, random results are drawn and continuously checked for similarity. After extensive training, the model learns “which description matches which type of image.”
When a text model is introduced, images need to be labeled during the training of the image model. For example, an image might be labeled as “a dog, grass, frisbee” or directly as “a dog playing frisbee on the grass” (this labeling process is often also done by AI). The model then “learns” that such images contain the three elements “dog,” “grass,” and “frisbee.” Through labels provided during training of other images, it determines what specific elements constitute “dog,” “grass,” and “frisbee.”
When the number of such images is extremely large, the AI “learns” the commonality of the “paths” (predicted noise) for generating these elements. During generation, it can search for the most suitable denoising method based on our input requirements (“keywords”). In each step of denoising, it checks whether the generated content matches the encoded information corresponding to the keywords, until the noisy image is denoised (generated) into an image that matches the keyword content.
The following example demonstrates the generation process of Stable Diffusion:

 Generation keywords: Golden Retriever,grass,(8k, RAW photo, best quality, masterpiece:1.2), (realistic, photo-realistic:1.37),cinematic lighting,best quality, ultra high res, (photorealistic:1.4),ultra-detailed, extremely detailed, CG unity 8k wallpaper,best illustration,high resolution, film grain, Fujifilm XT3
Generation keywords: Golden Retriever,grass,(8k, RAW photo, best quality, masterpiece:1.2), (realistic, photo-realistic:1.37),cinematic lighting,best quality, ultra high res, (photorealistic:1.4),ultra-detailed, extremely detailed, CG unity 8k wallpaper,best illustration,high resolution, film grain, Fujifilm XT3
This is a set of examples showing how an image is generated through 20 sampling iteration steps. The generation keywords consist of Golden Retriever, grass, and some words used to specify a realistic style. The number after “Steps” in the image represents the iteration count for the image below.
At the 1st and 3rd iterations, we can see only a blob of orange and a patch of green color blocks, indicating that the AI first identified the greatest commonalities in the training set for “Golden Retriever” and “grass”: orange and green. By the 5th iteration, as the image continuously iterates (denoises), the outline of a dog can be seen, though some strange color blocks remain, and the grass is not yet clear. However, the difference between the grass and the distant sky can already be distinguished. By the 10th iteration, a golden retriever on grass is clearly visible. From the 12th to the 20th iteration, the AI continuously refines and adjusts the image, making the golden retriever and grass more closely match the characteristics of “Golden Retriever” and “grass” in the training set.

From the iteration examples, we can clearly see how Stable Diffusion goes from a blurry blob of color to gradually generating an image that matches the keyword content. Although the final product still has a slight “oily feel” and can be somewhat distinguished from real photos, it is precisely this “oily feel” that proves AI does not simply collage from a database, but has its own unique way of generating images.
IV. Determining Whether Generated Results Are Infringing Based on the Principles of the Diffusion Model
1. Both Training and Generation of the Diffusion Model Reflect “Commonality”
From the above principles of training and generation, it can be seen that during training and generation, the diffusion model does not simply imitate a specific element of a particular image in the dataset, such as lines, composition, or color. Nor does it engage in so-called “retrieving images from a database for stitching.” Instead, it analyzes the commonality of a certain element across these images, starting from a noisy image through stepwise denoising and adjustment, to generate a result that conforms to this commonality.
The AI does not know what “apple” means, nor does it pick an “apple” from a database and slightly modify it before showing it. It only knows how to allocate pixels in the noise map to better match the content labeled as “apple” in the dataset, and the spatial distribution of those pixels.
From a collection of apple images, it learns the commonality of “apple”—shape, color, etc. From a collection of oil paintings, it learns the commonality of “oil painting”—texture, brushstroke, etc. From a particular artist’s portfolio, it learns the commonality of the “artist’s style”—color choices, composition, etc.
 With an additional ink-wash style training model, it can even generate images in the style of traditional Chinese painting.
With an additional ink-wash style training model, it can even generate images in the style of traditional Chinese painting.
2. Generally, Works Created Based on “Commonality” Should Not Be Considered Infringement of Copyright in the Training Set Works
The vast majority of human painting learning processes begin with imitation. After mastering the commonalities of “beauty” and “nature”—such as light and shadow, lines, composition, structure, proportion—and through continuous practice and adjustment, they gradually create works with their own style. The training and generation of diffusion algorithm model AI programs represented by Stable Diffusion precisely replicate this process. The difference is that what humans learn from are the natural laws observed through the eyes and the works of others, while what AI learns from is the image content provided by the trainer.
According to the Copyright Law of the People’s Republic of China, copyright owners have rights including the right of modification, the right to protect the integrity of the work, the right of reproduction, and the right of distribution. However, looking back at the training process of the diffusion algorithm model, there is no modification or destruction of the dataset works in any form (the process of adding noise during learning is clearly not legal destruction). The generation process based on “commonality” also does not involve any reproduction, distribution, or exhibition of the works in the original dataset. Furthermore, current law does not allow any individual to have exclusive rights to a certain “painting style.” Therefore, even if an author’s collection of works is used for training a “style,” the final work only incorporates the artistic commonalities of that style in the image, rather than being a plagiarism of a specific work.
3. However, “Overfitting” May Lead to Excessive Similarity with Training Works, So Judgment Should Be Based on the Specific Circumstances of the Model
“Underfitting” and “overfitting” are both erroneous training results in deep learning and machine learning models. The former is caused by too much data and insufficient training, leading to an inability to generate results with “commonality.” The latter is caused by too little and too specialized data, leading to generated results that are too similar to the training set content.
Just as a person cannot imagine something they have never seen, suppose a training set contains only 5 differently labeled works. After multiple rounds of training, the resulting model may “overfit,” and its understanding of a certain “element” may only come from those 5 works, leading to the generated work being a reproduction of one of those 5 works.
In this case, even if the generation process still involves finding “commonality” through denoising, because the “commonality” originates entirely from a single work, the generated content may be too similar or even identical to that work. At this point, arguing that the generated work does not infringe the copyright of the training set works based on the principles of the model algorithm would clearly lack persuasiveness.
V. The Algorithm Model Used in AI Works Should Be the Core of Infringement Review
Through the above analysis, we can see that different AI-generated work algorithm models have different working principles. Particularly for the currently popular diffusion model, under normal circumstances, the works it generates typically do not infringe upon the rights of a specific work in the training set. However, if “overfitting” occurs, or if specific content LoRA models (Low-Rank Adaptation of Large Language Models) or low-redrawing “image-to-image” methods are used, leading to excessive similarity with the original images or specific content of the training set, separate discussion is needed.
1. Considering a Work Infringing Simply Because It Is AI-Generated, While Ignoring the Actual Principles of the Algorithm Model, Can Easily Lead to Overprotection.
There are certain differences in the creative process and principles between AI-generated works and manually created works, but there are also commonalities. The principle of most AI-generated work algorithm models is to analyze large amounts of information and data, learn to obtain “experience” or “commonality” in a certain field, and on this basis, create new works, rather than simply copying, transplanting, or splicing a specific work from the training set. If this technical principle is ignored and a work is deemed infringing simply because it was generated by AI, it not only fundamentally misunderstands AI’s creative approach but also inappropriately restricts the development and application of AI technology in the field of cultural creativity.
Taking the example in this article, the artistic works generated based on the diffusion algorithm are created by machines that learn the “commonality” and “rules” of a large number of similar artistic works. According to the user’s needs, the “commonalities” and “rules” of different content are combined in the most realistic logical way to create new works. This process does not directly use a specific work, and is essentially no different from a human learning the technique of “oil painting” and then creating a new “oil painting,” or learning the technique of “ink wash painting” and then creating a new “ink wash painting” work.
If a work is defined as infringing on the training set works simply because it was generated by AI, it is equivalent to attributing all the “commonalities” and “rules” in a certain field to a specific person or group. This undoubtedly exceeds the protection scope of the Copyright Law and constitutes obvious overprotection.
Now that AI software has become accessible to everyone, anyone can generate the content they want using AI software without needing a long time to learn a specific professional skill. This will help stimulate creativity in general, shifting the core of “creation” to “creativity” and avoiding the inability to “create” due to lack of skill. However, if certain “commonalities” and “rules” are deemed to be mastered only by those who have the ability to “create,” and all AI software based on learning these contents is considered infringing, this would not only hinder the development of social creativity but would also directly negate the development of AI technology. After all, like humans, AI cannot imagine (create) content it has never seen (trained on).
However, except for algorithms similar to the diffusion model, it is also possible that there are algorithms that genuinely combine training set works. Therefore, to avoid overprotection, when determining whether an AI work infringes copyright, the actual working principle of the algorithm model should be considered, rather than simply making a conclusion based on its AI-generated nature.
2. Assuming All AI Works Are Non-Infringing, While Ignoring the Specific Usage of the Algorithm Model, May Lead to Underprotection.
Different AI-generated work algorithm models use data and information in different ways. Some models work by generating new works based on the training dataset. If the training data contains a certain original work and the algorithm model cannot effectively avoid overusing that original work, the generated AI work may likely constitute infringement. If the specific usage of the algorithm model is ignored and all AI-generated works are uniformly deemed non-infringing, the rights of the original work owners may not be reasonably protected in such cases.
For example, if the training corpus of a text generation model contains only a few novels, or even only works by a single author, and the model’s algorithm cannot avoid directly transplanting or extensively borrowing the characters, plots, and language of that novel, the generated AI work may likely infringe the exclusive rights of the original novel rights holder. In this case, if it is simply deemed non-infringing because it is an AI work, the fact that the algorithm model is overly reliant on and excessively uses the original work is being overlooked, leading to insufficient protection of the original work rights.
Similarly, Stable Diffusion based on the diffusion model also supports loading LoRA models to make the generated work lean more toward a certain result. Many users, when creating LoRA models, may choose to train based on a specific real person or fictional character, causing the final AI-generated work to contain that person or character, potentially leading to infringement of portrait rights or copyright of a certain character. If the possibility of infringement is categorically denied simply because it is generated based on a diffusion algorithm, it undoubtedly ignores the specific way the algorithm model uses data and the user’s malicious intent, failing to provide due protection to the rights holder.
To ensure the protection of rights holders’ rights, when judging whether an AI work infringes, the specific way the algorithm model on which it is based uses data during training and use should be carefully considered, and due attention should be given to situations that may lead to underprotection.
3. Taking the Algorithm Model as the Core to Confirm the Legal Status of AI Technology Helps Promote a Positive Interaction Between AI Technology and the Law.
As the technical foundation of AI-generated works, the legal status of algorithm models is still unclear. Currently, only the “Internet Information Service Algorithm Recommendation Management Regulations” regulates the use of “algorithm recommendations,” while the draft “Generative Artificial Intelligence Service Management Measures (Draft for Comments)” has been widely discussed in the industry due to significant differences from the actual situation of generative AI. If algorithm models can obtain practical legal regulations, such as determining whether the training set constitutes fair use, the copyright ownership of generated works, and the specific rights and obligations of algorithm creators and users, this will help AI model developers and users understand relevant legal risks, encourage more developers and investors to invest in innovative algorithm model research and development, and promote the development and application of AI technology in a wider range of fields, further demonstrating its role in various industries.
At the same time, from the current online discussions on AI technology, it can be seen that the legal academia’s understanding of emerging technologies such as AI is still not deep enough. This may lead to some legal analyses and viewpoints drawing conclusions without fully understanding the principles and characteristics of the new technology, and their conclusions may be overly subjective and ignore objective factors. Compared to past technologies, emerging technologies such as AI, when combined with algorithm models and other content, are often more complex and difficult to understand, which poses significant challenges to relevant legal analysis. Taking AI-created works as an example, if one cannot understand the working methods and principles of different algorithm models, it will be difficult to make appropriate analyses and conclusions regarding infringement judgments and protection. Furthermore, if the legal academia cannot keep pace with the development of new technologies and fully understand their inherent principles and characteristics, it is easy to deviate when formulating regulations, making judicial judgments, or conducting risk analysis due to difficulty in accurately grasping the essence of new technologies. This may lead to a situation where the law is too far ahead of technological development, hindering the application and promotion of new technologies.
If the legal academia fully studies and researches the principles of algorithm models and clarifies the infringement judgment method centered on algorithm models, it will help the legal academia make more rigorous judgments on AI technology and develop more practical laws and regulations. This will reduce the risks for AI technology developers and users, encourage the design and development of more innovative algorithm models, and promote the application of AI technology in a wider range of fields, especially in the cultural and creative industries. This will not only benefit the vigorous development of the AI industry itself but will also enrich human spiritual life and promote social progress.
[1] Difference Between Algorithm and Model in Machine Learning https://machinelearningmastery.com/difference-between-algorithm-and-model-in-machine-learning/
