Common Misunderstandings About DeepSeek in the Legal Industry (Part 1)
Debunks widespread misconceptions about DeepSeek circulating in China's legal profession, including the myth that reasoning models always outperform regular models, that web search guarantees accuracy, and that chat input constitutes model training.
Recently, with the DeepSeek craze, various tip-sharing articles have been circulating online.
Many of them are published by professional legal institutions, law firms, lawyers, and legal departments.
This craze already appeared when GPT-3.5 was released years ago. With the surge in DeepSeek’s popularity, the legal industry has started again, with even more people joining this time.
But puzzlingly, many long-standing misunderstandings and misconceptions are being shared again as “tips.”
Some even include a lot of “made-up” content that’s really hard not to laugh at.
Let’s take a look at what these misunderstandings are and just how离谱 they can be.
*This article represents the author’s personal opinions and should not be considered as legal advice or opinions.
**Screenshots in this article are for illustration only and are not intended as criticism of the original authors.
I. Common Basic Misunderstandings
Let’s start with a few common misconceptions to help evaluate the various “misguided tips.”
Misunderstanding 1: The DeepSeek reasoning model is the best, so don’t use the regular model
Reality: The reasoning model can overthink due to repeated “multi-angle thinking”
Official V3 (regular model):
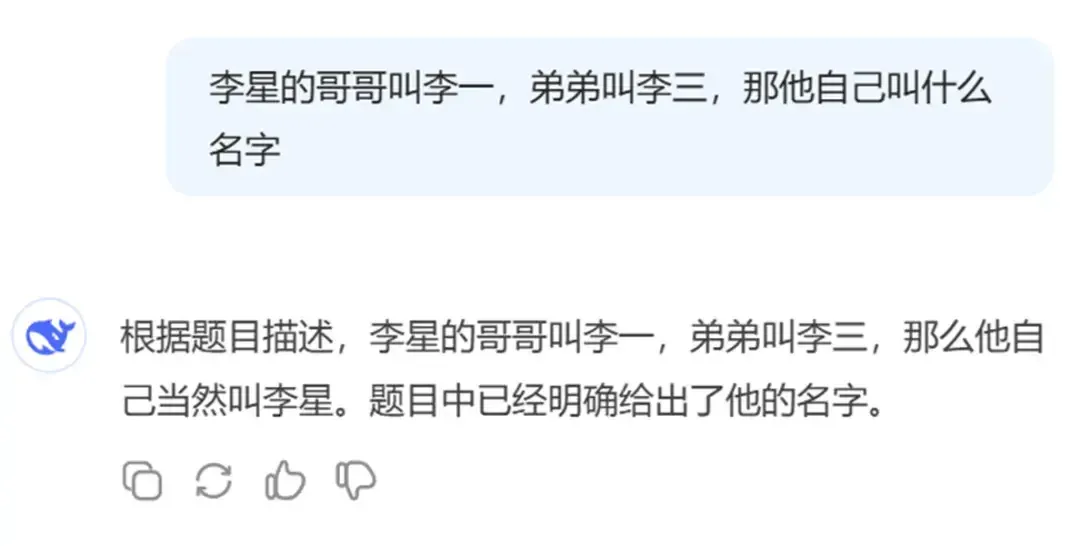
Official R1 (reasoning model):

After lengthy reasoning, R1 actually arrived at the correct answer during its thinking process, but due to too many angles of consideration, it ultimately contaminated the final output.
For questions that don’t require excessive reasoning, using the reasoning model indiscriminately can easily lead to incorrect results.
Misunderstanding 2: DeepSeek’s answers are always correct
Reality: The core principle of current large language models (LLMs) is “predicting the most likely next word based on context,” not truly understanding the content. No LLM can fully guarantee the correctness and truthfulness of its output—this is known as the “hallucination” problem.
Only a very few AI models engage in some level of “thinking” or “judgment” before answering. The vast majority of AI models directly generate responses based on user input and will not actively refuse to respond (unless encountering explicitly restricted questions). Even when faced with content that never appeared in the training data, AI will generate seemingly reasonable but potentially inaccurate answers based on word probability distributions.
Moreover, AI cannot even guarantee the accuracy of summarizing text content.
Combined with the next misunderstanding, everyone will have a clearer understanding of AI’s limitations.
Misunderstanding 3: Web search is trustworthy
Reality: The principle of web search is to send the user’s question to a search engine API, retrieve web results, and then have the AI summarize this content directly to answer the user’s question. AI does not judge the authenticity of the content. Therefore, the accuracy of the response entirely depends on information published by others in the web results.
Even AI can make errors when summarizing web content.
Here’s an example:
When using DeepSeek’s web search function, asking: “Please analyze case (2025) Yue 0103 Min Chu 9999.” DeepSeek then initiated a web search, retrieved 50 web pages, and returned a seemingly detailed answer. The answer covered the case background, judgment result, legal procedures, significance, etc., and even included source information, making it appear quite credible.

However, just by looking at the titles of the source links, obvious problems are already apparent: the actual case comes from the Guangzhou Panyu District People’s Court, and the case number is completely different.
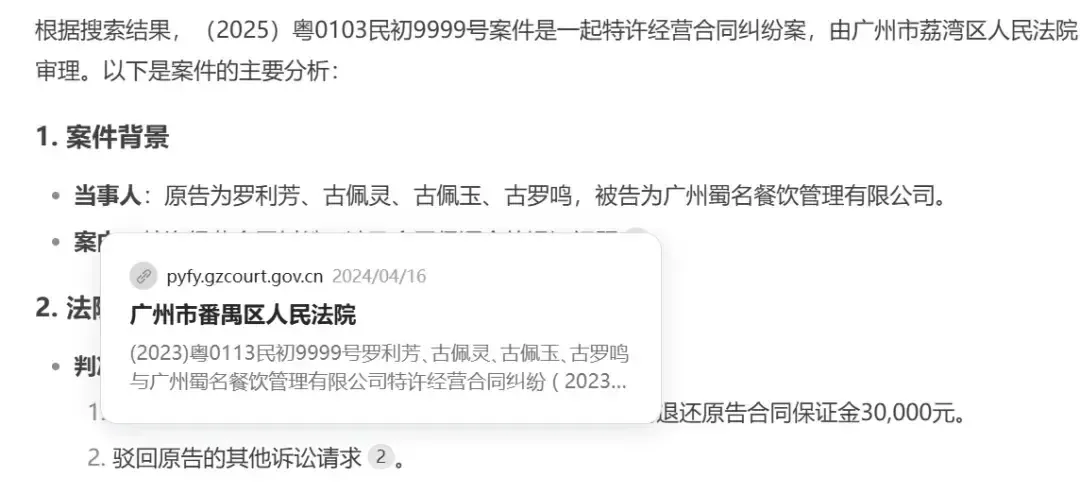
The actual web content looks like this:

How many errors were in DeepSeek’s answer?
-
Wrong case number: The actual case number was “(2023) Yue 0113 Min Chu 9999,” but it was incorrectly written as “(2025) Yue 0103 Min Chu 9999.”
-
Wrong court: The actual court was the Panyu District People’s Court, but it was incorrectly identified as the Liwan District People’s Court.
-
Wrong appellate court: The appeal should have been to the Guangzhou Intellectual Property Court, and the appeal documents should have been submitted to the Panyu District People’s Court, not the Guangzhou Intermediate People’s Court as misstated.
-
Wrong legal basis: The notice only involved procedural service issues, not case trial based on the Civil Procedure Law of the People’s Republic of China.
-
Wrong document type: It was actually a service notice, not a judgment.
These errors came solely from DeepSeek summarizing a single simple webpage (within context limits). If the data came from more webpages, and each page contained lengthy content exceeding AI’s context window, the error rate and unreliability could increase further.
Even with web search enabled, the “hallucination” problem cannot be fully eliminated. Each source of information must still be verified one by one.
Never take any AI-generated output text at face value.
Misunderstanding 4: Feeding/training your own AI in a single chat window
All current large language models (LLMs) on the market have a significant limitation: context length is finite. Although some models have extended context to 1M or even 2M (about 2 million tokens), they still cannot escape the essence of being “limited.”
Many people think that by continuously inputting their materials into the chat window, they can make the AI “learn” or “remember” this content, achieving so-called “feeding” or “training.”
However, this idea is actually a misunderstanding and is not true training at all.
First and foremost, AI’s “knowledge” mainly comes from the parameters of its initial training, not from temporarily input user data.
In the chat window, the materials provided by the user serve only as the current session’s temporary context. AI combines this content with its own parameters to generate responses. But when the conversation exceeds the context window limit, earlier information is automatically discarded, and the AI can only refer to subsequent content. This is why “single-window conversations get dumber over time”—the earliest text has long been forgotten.
AI does not accumulate knowledge like humans do, nor can it improve its understanding of a particular domain through repeated input in a single session. Even if you cram a massive amount of information into one window, once you open a new window, the AI will still have “amnesia,” because its “memory” is limited to the finite context of a single session.
True AI training requires professional technical frameworks, massive amounts of annotated data, and complex backpropagation algorithms to adjust model weights—not simply piling materials into a chat box.
Of course, the content users input may be collected by AI companies as material for training the next generation of models, achieving another form of “training,” but that’s a different topic.
II. Various “Interesting” Tips
Due to maximum context limitations (laughs), I’ll stop here for basic AI knowledge sharing. Let’s now look at some of the various “interesting” tips I’ve seen online recently.
Even someone like me, an experienced AI user, couldn’t help but be amazed.
Note: The following examples are from publicly available public account articles, used only as excerpts for illustration (there’s too much content, so I’m only showing a few that I found most remarkable). If these tips actually work and I’m just ignorant, I apologize in advance.
”Tip” 1: DeepSeek automatically crawls the web

Without API integration, DeepSeek cannot automatically crawl any latest regulatory updates regardless of instructions. Moreover, web crawling is not within an LLM’s capabilities—it’s the work of crawler programs/web search APIs.
Additionally, DeepSeek cannot generate images (though it can display them through generated HTML, but among the sharing articles I’ve seen, very few know that DeepSeek has HTML display capabilities).
”Tip” 2: DeepSeek can do similar case searches



In reality, DeepSeek does not have access to any case database and does not possess the ability to perform “similar case retrieval.” As we know from the misconceptions above, even with web search enabled, it’s unlikely to directly embed search results into a report.

It also does not have the ability to quantify probabilities based on historical judgments.

Similarly, it cannot filter out key cases.
(If using API to read through each document one by one, RIP API costs.)
”Tip” 3: DeepSeek can improve accuracy through feedback commands

DeepSeek does not have a /feedback command, and as mentioned earlier, normal user replies are not used to train its own model. Whether or not you use such commands has no effect on future usage.
The two buttons that actually help with DeepSeek’s training are these, used for human preference fine-tuning:

So if you want to help DeepSeek train, feel free to click these two buttons.
”Tip” 4: DeepSeek has a “revision” mode

DeepSeek can only output content in text format. It does not have a “revision mode” feature, nor can it directly operate on Word or WPS.
If you really need such functionality, I recommend using my Word/WPS plugin:
”Tip” 5: DeepSeek can parse hash values
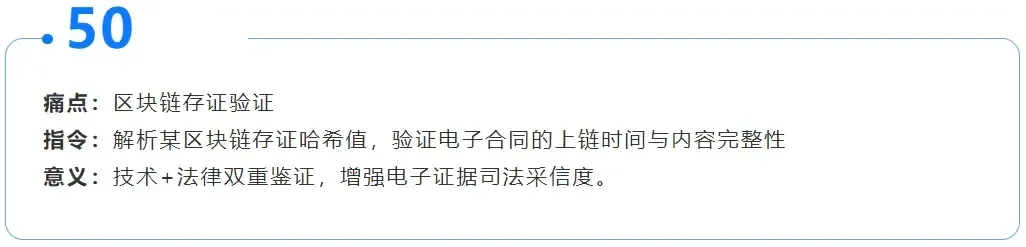
DeepSeek is just a large language model. It does not have the ability to verify hash values, nor can it be used to verify blockchain on-chain time or content integrity.
”Tip” 6: DeepSeek can check and adjust formatting
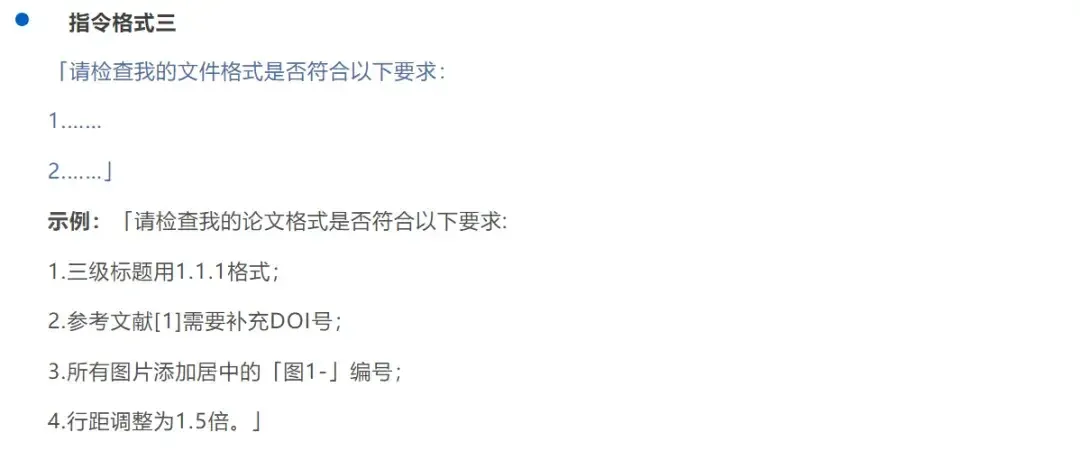
All text input to DeepSeek is automatically converted to plain text format. Regardless of the original format, everything sent to DeepSeek is plain text.
Similarly, DeepSeek’s output won’t include any formatting data like “centering” or “line spacing.” Heading formats are also output in plain text. You still need to manually adjust formatting in Word or WPS.
In fact, because the entire text has been modified, there’s even more formatting to fix.
”Tip” 7: DeepSeek can transcribe audio files

DeepSeek is a relatively “pure” large language model. It doesn’t have any audio transcription capabilities, let alone the ability to distinguish speakers in audio or know who is Party A and who is Party B.
In fact, DeepSeek doesn’t even have image understanding capabilities—it can only OCR text from images.
”Tip” 8: DeepSeek can replace “XXCha” (business information platforms)

Unless integrated with an “XXCha” API or a self-built enterprise information database accessed through API workflows, DeepSeek cannot conduct due diligence simply based on target entity information.
Moreover, unless you provide all the above data at once (and it doesn’t exceed the maximum context limit), DeepSeek cannot analyze “the performance of major contracts and whether there are potential legal disputes,” because DeepSeek doesn’t have this data. Forcing DeepSeek to answer will only result in a fabricated conclusion (“hallucination”).
”Tip” 9: DeepSeek can “forget uploaded content”

No one can make any changes to DeepSeek’s servers through the chat window.
When using DeepSeek or other AI, whether it’s text input by the user or files uploaded to the AI, they will be stored on the AI provider’s servers for a limited period or indefinitely. Currently, no user instruction can require the AI to perform any recall or deletion.
This relevant data becomes a source of parameters for training DeepSeek’s next-generation models (the same applies to other model services).

(Moreover, if a user could actually manipulate DeepSeek’s servers, what would happen if someone gave the command “format your server”?)
III. Temporary Conclusion
Due to space constraints, I’ll stop here for now with Part 1. As a lawyer, I sincerely hope I won’t need to write Parts 2, 3, and 4—after all, writing educational content takes far more effort than creating buzz.
I don’t mean to criticize anyone with this article. I just want to appeal from a lawyer’s perspective: In the legal profession, evidence is king and logic is fundamental. When writing articles or chasing hot topics, can we first return to our professional instincts and verify the authenticity of the materials? Instead of hastily “referencing” a few public account articles, or even having AI generate usage guides for you—this is far from the rigorous attitude we pursue in court.
Especially when we speak as law firms or professionals, every article carries the public’s trust in legal professionals. Short-term traffic may be tempting, but if the content is inaccurate, it damages not just personal or firm credibility but also the entire profession’s standing in the public eye.
As legal professionals, every “educational” piece and every “sharing” should be like courtroom arguments—guarding the foundation of facts, not paving the way for rumors, and certainly not compromising for traffic.
If even legal professionals abandon truth in pursuit of trends, how can the world trust the authority of the law?
