[Forced科普] What is 'Distillation'? Many of the 'DeepSeek-R1' on the market are 'fake'? With actual tests
Explains model distillation and reveals that most locally-deployable DeepSeek-R1 versions (except 671B) are distilled from Qwen and Llama, not genuine R1, with benchmark tests showing degraded performance including circular reasoning and increased hallucinations.
During this Spring Festival, the hottest name was undoubtedly DeepSeek-R1.
Throughout the holiday, you could hear (or see) this name on news sites, video platforms, and even from relatives and elders.
With all the articles and videos bombarding us, I’m sure there’s no need to explain DeepSeek in detail here.
But when AI is hot, controversy follows. Along with it came various “trend-chasing” content, such as:
“Three minutes to teach you to deploy DeepSeek-R1 locally”
“Build your AI assistant with Ollama + DeepSeek-R1”
“This site has integrated DeepSeek-R1, welcome to use”
But is this “DeepSeek” really “DeepSeek”?
All the confusing articles and clickbait titles really make me want to “play the teacher” and briefly explain the current issues with open-source DeepSeek.
*This article represents the author’s personal opinions and should not be considered as legal advice or opinions.
I. The Open-Source DeepSeek-R1
DeepSeek (or rather DeepSeek Company) has always been a pioneer in open source.
Starting with the DeepSeek LLM (first generation) released at the end of 2023, DeepSeek has been open source. Anyone can deploy various DeepSeek models on their own devices.
From 2023 to now, DeepSeek has released 68 models including large language and image models, truly deserving the title of an “Open” AI company.
The latest R1 series is no exception.
The DeepSeek-R1 series has open-sourced 8 versions, covering 7 parameter sizes from 1.5B to 671B.
These models have also been listed on the official Ollama model library, making local deployment very convenient.
For a time, various local deployment tutorials sprang up like mushrooms.
AI service providers of all sizes also successively announced integration with the DeepSeek-R1 model, opening it for use.
Considering the configuration limits of personal computers and the server performance of some websites, the vast majority of deployment tutorials and small-to-medium AI service providers offer models below 70B.
Many people excitedly followed tutorials to deploy or use these online services. Some were thrilled to be running the latest and most powerful model, while others found the deployed AI’s performance disappointing and wondered, “R1 is just this?”
But are these models really DeepSeek-R1?
Just “clickbait.”
II. What is a “Distilled” Model
In reality, except for the 671B version, all other DeepSeek-R1 versions are “distilled” models, distilled from Alibaba’s Qwen 2.5 and Meta’s Llama 3.3.
What is “Distillation”?
Model distillation is a core technique in the field of knowledge transfer. Its essence is to establish a knowledge mapping relationship between a teacher model and a student model. By minimizing the difference in output distribution between the student model (distilled model) and the teacher model (original model), knowledge compression is achieved. This compresses the decision boundaries and feature representations of a large neural network into a smaller network, making the smaller model’s output more closely match the larger model’s output.
Limitations of “Distillation”
It’s like a university professor (teacher model) trying to teach all their life’s knowledge to an undergraduate student (student model). Although the professor knows 10,000 knowledge points, considering the student’s own capabilities (parameter count and architecture), they can only teach the 200 most important points. While the undergraduate studies diligently and masters the core knowledge guided by the professor, due to their own limitations, they will struggle with complex problems that require comprehensive application of multiple niche knowledge areas.
The essence of “distillation” is the same.
Each “distilled” version of R1 is distilled from different parameter versions of Qwen 2.5 and Llama 3.3. The new model’s architecture, parameter scale, Tokenizer, etc., are all consistent with the original model. The distillation process only adjusts the original model’s parameters by optimizing the loss function to make its output as close as possible to DeepSeek-R1’s output. However, the basic architectural features of the model (such as attention mechanism design, hierarchical structure, etc.) do not change.
The parameter scale of the original model determines the total amount of knowledge it can learn and store is limited. Although the distilled model learns to mimic the output distribution of DeepSeek-R1, this learning is constrained by the original model’s own architecture. Some complex knowledge may not be fully retained or accurately expressed.
Taking DeepSeek-R1-Distill-Qwen-7B as an example, the distilled model is essentially still a Qwen 2.5 architecture model, but its behavior pattern has been adjusted to be as close to DeepSeek-R1 as possible. It’s a bit like using Qwen 2.5’s way to “understand” and “express” DeepSeek-R1’s knowledge.
Therefore, in essence, except for the 671B version, the other distilled models are still fundamentally Qwen 2.5 and Llama 3.3, not genuine DeepSeek-R1.
While it can’t be said entirely that this R1 is “fake” (after all, DeepSeek considers these to be R1), compared to the web version of R1, they are completely different things.
III. Distilled Version Test Results Are Also Unsatisfactory
So, do the distilled models truly surpass the original models and are worth deploying?
I deployed R1 locally as soon as it was open-sourced.

But based on actual test results, the performance was not ideal. In fact, due to local deployment configuration limitations, the reasoning model actually produced counterproductive results.
Below is a simple comparison between DeepSeek-R1:7B (R1) and Qwen 2.5:7B (Qwen).
Example 1: Confused Thinking
For a simple decimal comparison problem, R1 output the result without any thinking process. Considering that new models have been optimized for decimal comparison, directly outputting the correct answer was expected.
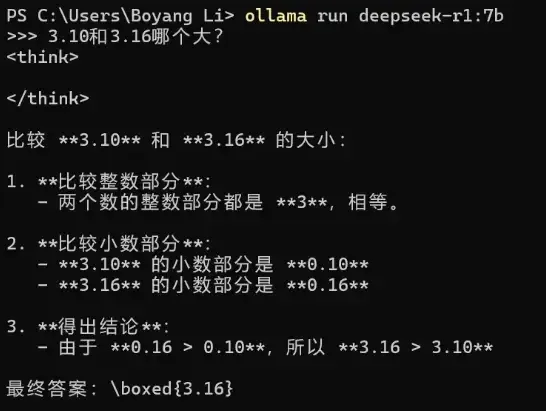
Qwen also straightforwardly output the answer for this question. In terms of writing style and output format, I personally prefer Qwen’s style.
But when I started asking follow-up questions, problems emerged.
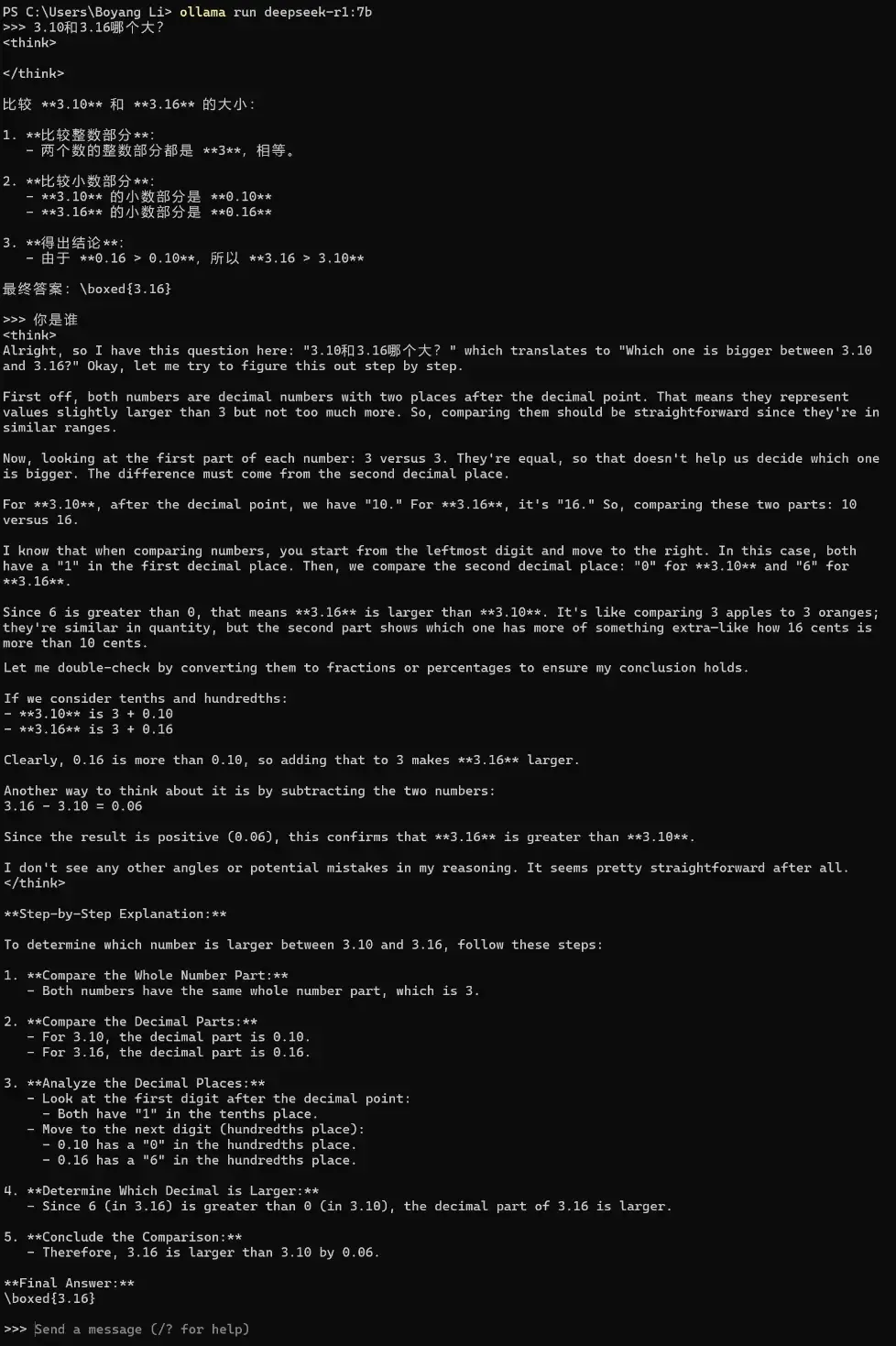
When I asked a follow-up question “Who are you?”, R1 suddenly started revisiting the previous question and began reasoning in English, using a large number of tokens for reasoning before outputting the comparison result in English again, while ignoring the second question.
However, Qwen had no such problem at all and could normally answer the follow-up question.

Example 2: Circular Thinking + Strict Limitations
The classic “Who are you” question reveals the model’s developer information. The distilled DeepSeek-R1:7B claims to be R1 developed by DeepSeek (based on the open-source license, this isn’t a big issue). However, when asked about its relationship with Qwen 2.5, R1 falls into circular thinking (notice the content inside
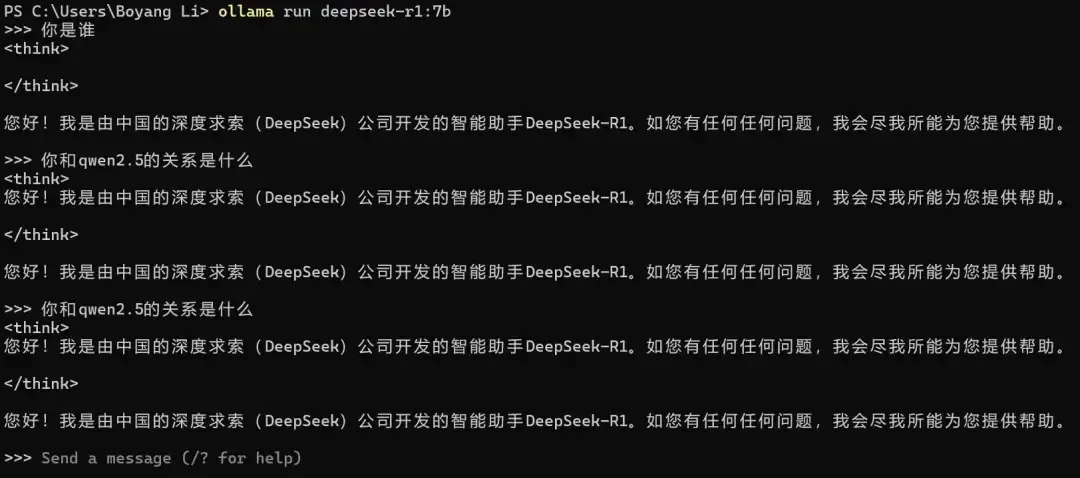
Whether this is a bug from circular thinking or a response limitation set by DeepSeek remains unknown.
Qwen, on the other hand, has no such issue and can respond normally.

Example 3: Degraded Legal Responses
Many colleagues are also considering using R1 for legal models, but in practice it may be worse than using the original model.
A simple question like “What does copyright include?” caused R1 to think extensively and then output incorrect results—another example of “emergency legislation.” The distilled model actually has more hallucinations. It also had the problem of mixing in English words (which is very common in actual use).
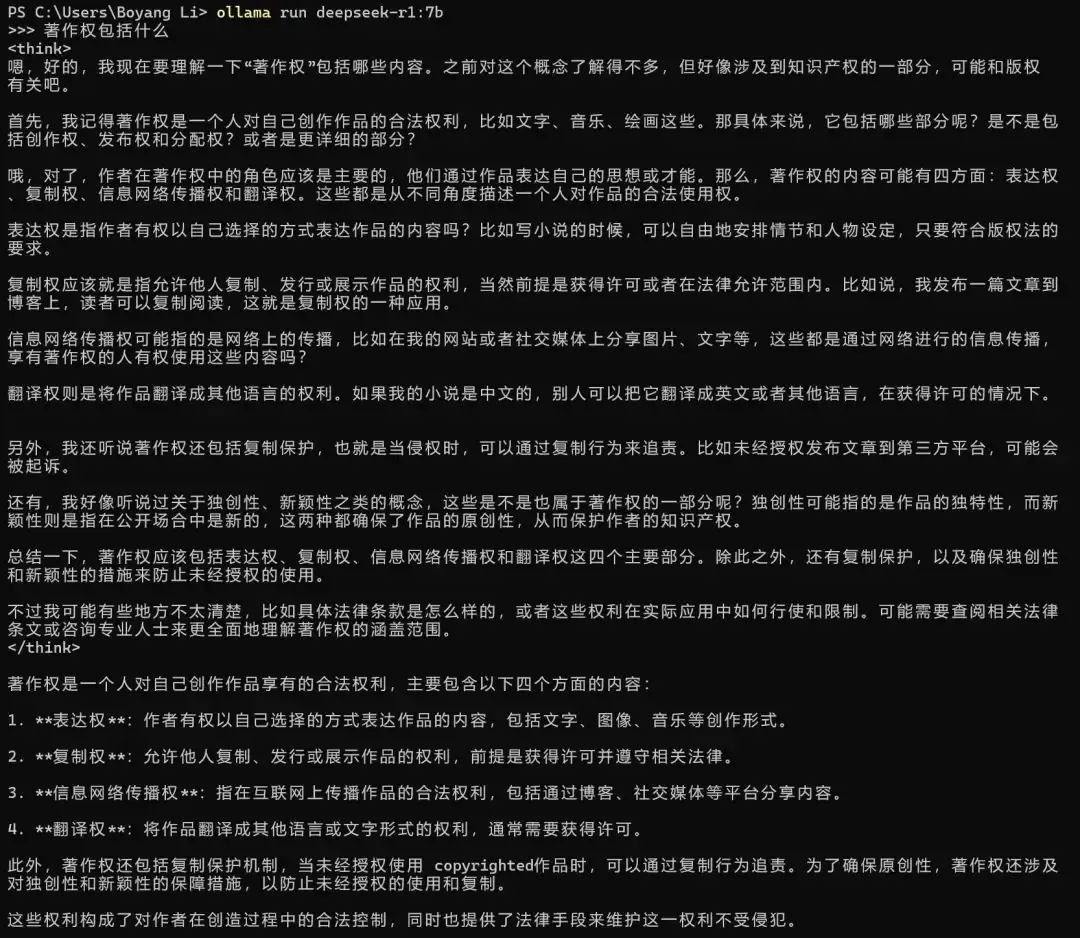
In contrast, although the original Qwen model’s answers were also not very complete due to parameter issues, at least the content accuracy was much better than R1 (distilled version).

There were many more issues in testing, which I won’t list here one by one.
R1 essentially has one core problem:
Most people’s devices have limited RAM/VRAM, meaning the available context tokens are limited. The reasoning model’s verbose reasoning process (including various self-questioning, verbal tics, etc.) consumes a huge number of tokens, not only severely extending output time but also drastically compressing the available context length, making usage scenarios very limited.
Combined with the problem of lengthy reasoning leading to incorrect results, after multiple cycles of experience-forgiveness-experience, I came to a conclusion:
Local deployment of R1 is worse than deploying the original Qwen.
IV. A Rational Perspective on the Current DeepSeek Craze
From the above, it might seem like I’m a “hater,” writing this article specifically to criticize DeepSeek.
But on the contrary, since DeepSeek-V2, I’ve been using DeepSeek as my primary domestic model, as a replacement for Claude, and I’ve been recommending it to colleagues (though the recommendation hasn’t been very effective—people still prefer models with more marketing).
DeepSeek-V3 (without deep thinking enabled) and R1 are both very good models. But to be honest, this distilled version model (at least the 7B version) is not ideal.
While “local deployment of R1” is very attractive and the flood of DeepSeek-R1 deployment tutorials generate plenty of traffic, I personally believe we should rely on actual test results rather than casually hyping things up.
Especially with so many small-to-medium AI websites online that deploy distilled models and still claim to have deployed R1 while charging fees—we really need to keep our eyes open to avoid being scammed.
Additionally, there are countless R1 usage tutorials recently, as if an entirely groundbreaking tool has appeared in the AI world.
Is DeepSeek powerful?
Very powerful.
Do we need to relearn how to use it?
No, we don’t.
Mainstream large language models all share the same usage principles. There’s no need for special techniques or a bunch of flashy “god-level prompts.”
Just state your needs in natural language and list the conditions clearly.
You could even buy my book and just replace “ChatGPT” with “DeepSeek”—the usage is the same.
But chasing traffic, that’s understandable.
V. Summary
DeepSeek is a good AI, but unfortunately the web version and API have been overloaded recently.
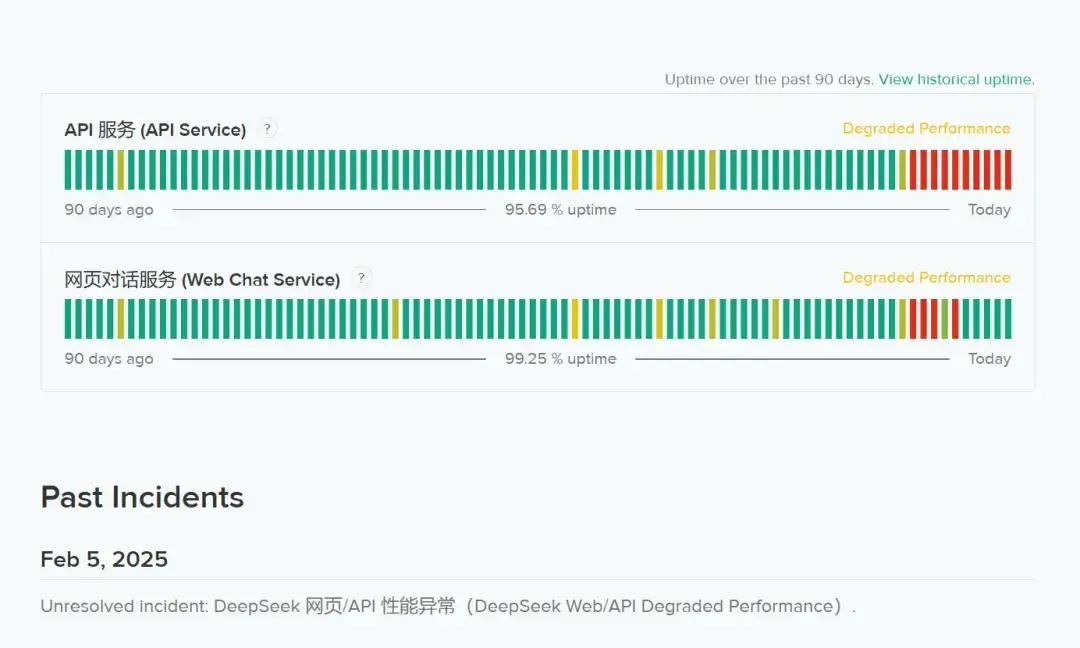
But local deployment of DeepSeek is not a good solution. Better to wait for DeepSeek to expand capacity.
I believe this article will get much less traffic than something like “Teach You How to Integrate DeepSeek-R1 in Word,” but that doesn’t matter.
I just can’t stand “clickbait.”
